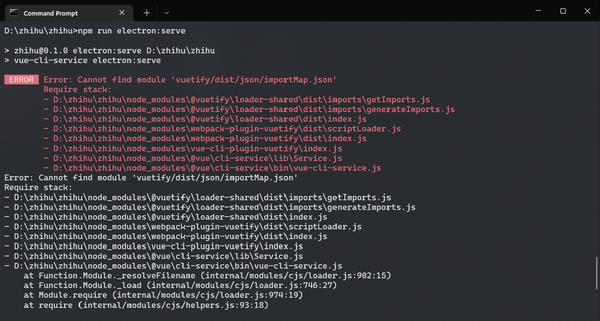
考虑到某些模块的正常运行离不开伪造http请求标头来欺骗服务器,以获取上面的某些敏感数据。
准备做一个应用内的定制版下载管理器,来承接各个模块可能需要触发的下载任务。
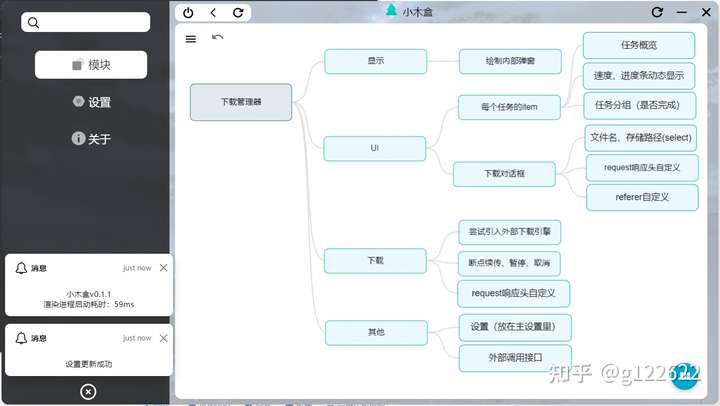
整个分支工程的框架大体如下:
一、外置下载引擎的可行性论证与选择
优秀的下载器motrix使用aria2作为其内核,支持断点续传和多进程下载。但因其技术文档难以寻找,我打算使用常见的request模块来下载文件。以后若有时间,我会把aria2也集成进去。
二、下载逻辑以及代码编写
1.作为一个独立对象储存在./insert/buildInDownloader
2.文件树目录结构:
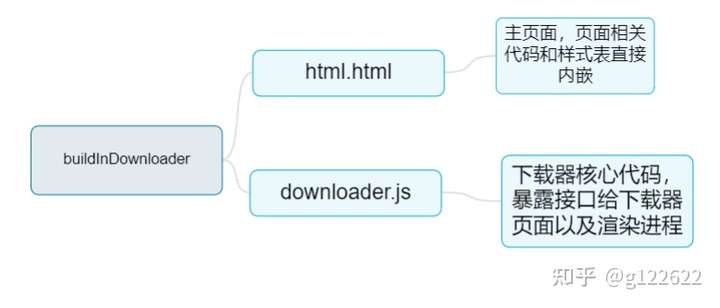
3.下载原理:
- 创建写入流 fs.createWriteStream
- get方法请求文件 request.get(options)
- 在request请求的回调函数中获取文件大小并设置length参数 length: response.headers[‘content-length’]
- 设置好length参数之后再重新request请求文件(否则无法获取length参数,进度信息会有误)
- 将request请求到的文件流pipe进progress-stream的实例(proStream)中去监听文件下载进度 request.get(options).pipe(proStream)及proStream.on(‘progress’, function(progress){…})
- 文件下载完成,触发文件的finish事件
4.代码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
| var request = require('request');
var progress = require('progress-stream');
var fs = require('fs');
var http = require("http");
var percentage = new Map();
var progress_stream_instance = new Map();
var file_write_stream = new Map();
function download(options) {
file_write_stream.set(options.task_id, fs.createWriteStream(options.save_path,{encoding:"binary"}));
var my_request = http.request({
method: 'HEAD',
path: options.path,
host: options.host
}, function (res) {
if (res.statusCode == 200) {
console.log(file_write_stream);
progress_stream_instance.set(options.task_id, progress({
length: res.headers['content-length'],
time: 500
}));
progress_stream_instance.get(options.task_id).on('progress', function (progress) {
percentage.set(options.task_id, Math.round(progress.percentage));
});
request.get("http://" + options.host + options.path, options).pipe(progress_stream_instance.get(options.task_id)).pipe(file_write_stream.get(options.task_id));
} else {
console.error('error');
}
});
my_request.end();
}
|
三、最终实现效果:
(TODO:暂停、断点、UI美化)
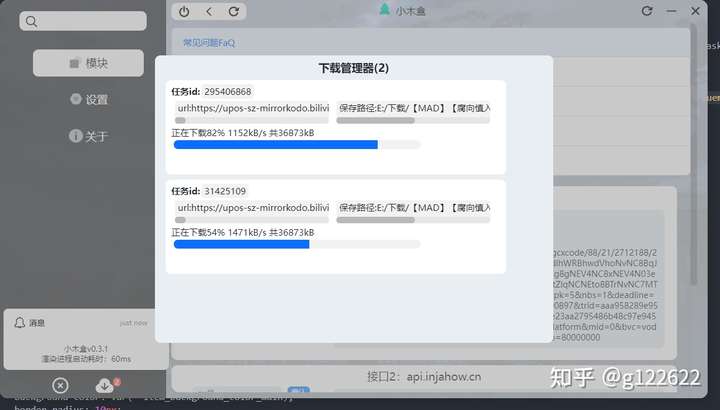
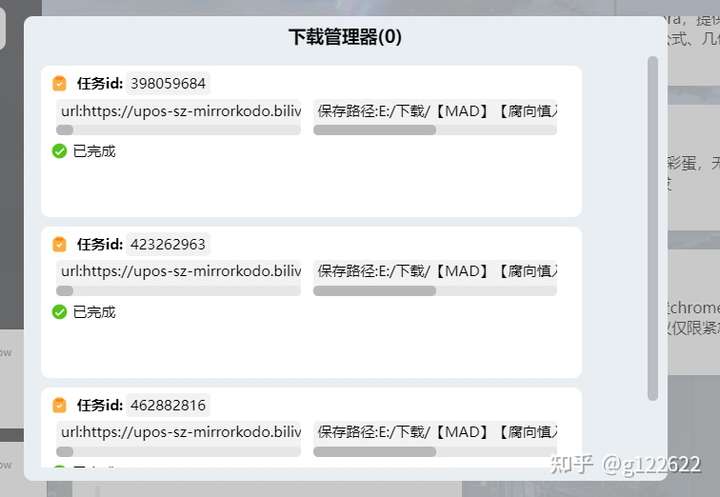
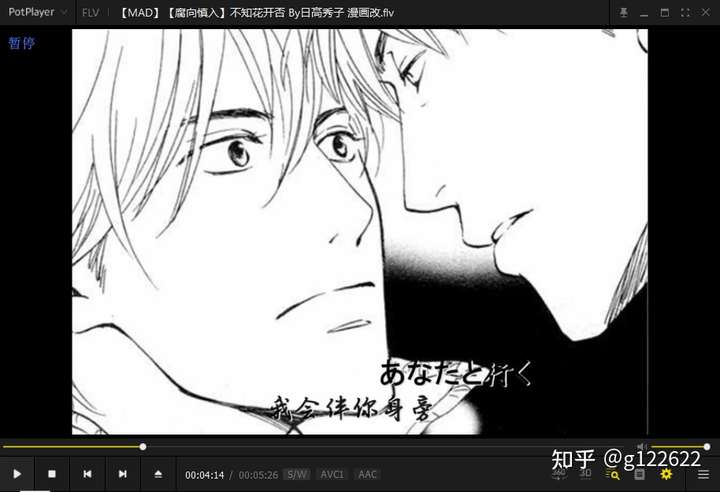
成功结果:最终从B站下载来的视频:
编辑于 2022-02-04 17:39