【万字长文】盘点Minecraft中的性能优化及其原理
【万字长文】盘点Minecraft中的性能优化及其原理
gy前言
🚧🚧🚧施工注意:本文尚未完成,作者正在努力填坑🚧🚧🚧
Minecraft是一款非常优秀的沙盒游戏,作为一名练习时长七年半的老玩家,笔者不仅见证了它的无数次迭代,也从最开始的萌新玩家成长为这款游戏的原理的研究者。
本文旨在从区块加载、地形生成、3D渲染、游戏机制、资源管控、数学运算等方面盘点Java版Minecraft中为了提升游戏性能而曾经采取的优化措施及其原理(除了官方优化之外,还包括optifine、foamfix、lithium等第三方优化mod)。
阅读本文前,你需要掌握:
- 较为完整的Minecraft游戏经验
- 一定的计算机知识(计算机语言、算法、数据结构、计算机组成原理等),够用就行
- 了解Minecraft基本技术概念,如:游戏刻、区块、实体、Client/Server模型、NBT数据格式
本文中出现的所有Minecraft源码仅供学习交流使用,取自Java版1.12.2和1.14.4,前者使用mcp提供的映射表反编译而来,后者使用官方map获得。所有源码在反编译的基础上已经过本人的适度修改,以确保和原版不同。
修订记录
2023.8.5 初稿写作完成
2023.8.14 文末追加了第五章-底层基础 JVM相关内容
2023.9.6 初稿发布
2024.2.5 在第四章-游戏机制 中增加漏斗的优化相关内容
2024.2.10 在第四章-游戏机制 中增加信标的优化相关内容
2024.5.30 在文首增加设计模式 一章
0.设计模式
Java版Minecraft的早期版本使用了较为传统的对象与继承的方式来表达游戏内容(包括但不限于实体、方块)的行为和属性,以及复用和扩展功能。
下面以Java版1.12.2中的牛(EntityCow,继承自EntityAnimal)为例,说明这一观点:
1 | |
这种设计模式,将逻辑和数据紧密耦合在了类内部,在Minecraft迅猛发展的早期阶段也许可以更快、更直观的实现需求,但是随着游戏逻辑日渐复杂、玩家对游戏性能要求日益提高,渐渐力不从心了起来。更何况Java中的类只能实现单一继承,如果需要从多个父类继承行为,就必须寻找其他work-around(如接口),无疑增加了代码的复杂度。
从性能上看,过度使用继承最后会导致“类爆炸”,即为了适应各种细微的差异创建大量类,不仅难以管理,而且大量的同类别数据在runtime会分散在不同的对象中,破坏了内存的空间局部性,不利于充分利用CPU Cache。
为了缓解由此设计模式引起的种种问题,同时提高性能和可维护性,Minecraft后来的版本开始逐渐引入了ECS模式,将数据(组件)与逻辑(系统)解耦,尤其是在基岩引擎的编写中。笔者在使用IDA逆向基岩版Minecraft时,发现了不少ECS的痕迹:
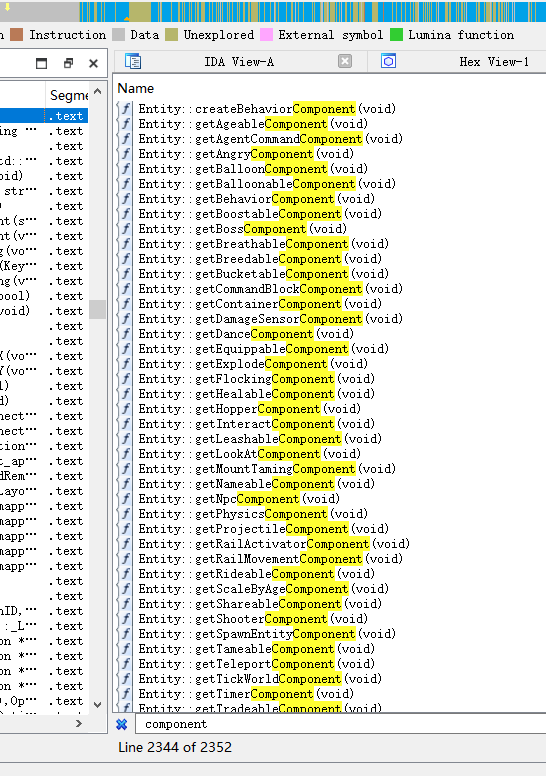
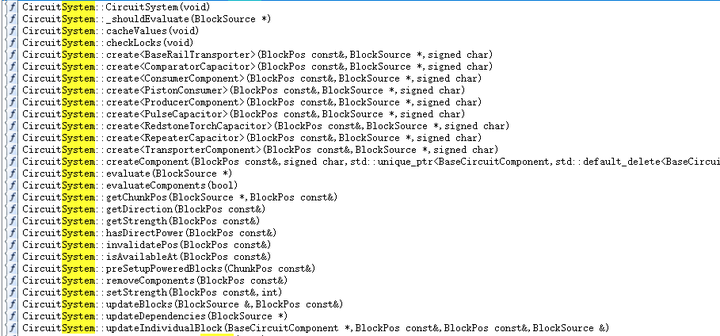
相比于传统模式,ECS是如何实现性能优化的?ECS架构通过以下几个关键点来提高性能:
- 数据局部性与缓存友好:ECS设计鼓励数据扁平化存储,将相同类型的数据放在一起,这样可以最大限度的利用CPU Cache。当系统处理Entity时,由于相关数据紧密排列,内存局部性较强,减少了Cache-Miss。
- 并行处理:ECS架构天然适合并行计算,不同系统之间通常没有依赖或很少有依赖,可以并行运行多个系统,有助于避免Minecraft成为单核游戏。
- 组件复用:多个Entity可共享同一组件,减少内存占用,并且由于组件类型固定,可以预分配、优化内存布局,进一步提升性能。
1.区块加载与地形生成
1.1 区块的存储
使用NBTExplorer打开存档下的一个.mca区块文件,你将得到类似下图的NBT可视化结构图。下面我们回顾一下它的过往。
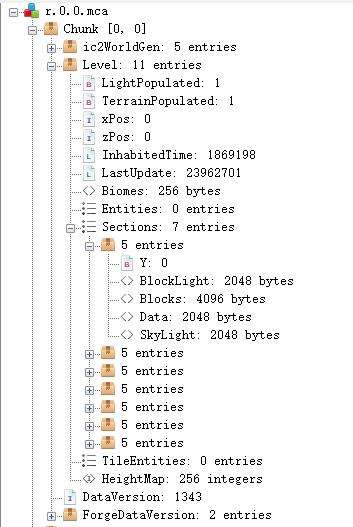
远古时期,知名模组Optifine的作者Scaevolus启动了MCRegion项目,被mojang官方认可,成为自Beta1.3之后Minecraft的御用区块存储系统。时过境迁,在Minecraft正式版1.2更新后,MCRegion被新版区块存储系统——Anvil所取代,旧版.mcr区块文件后缀也更改为.mca。也许是先前的Mojang起点太低、优化空间极大,Anvil不负众望,带来了许多可观的性能优化:
- 世界上的空的区域并不会占用内存或保存至硬盘内。

如图所示,与Linux下的Ext文件系统组织模式类似(引导块+块组),region文件也有一个8KB的NBT格式头部,其后就是各个区块的数据了。每个区块的偏移量固定,可通过固定的算法解算。一个区块数据的总大小最大为1MB。如果区块还未生成或还未迁移,则该部分会全部为零。但这也导致大量空间被浪费。Anvil则解决了这一问题。
方块的排列顺序从XZY改成了YZX来提高压缩率。这个我还不太清楚什么原理…
优化了发送给客户端的区块数据包(一个无空气的区块要比在旧格式的同区块更小,一个拥有很多空气的区块更是要小得多),区块内全为空气的section将不会被储存和发送。
此外,值得注意的是,无论是MCRegion还是Anvil,都采取将32*32共1024个区块封装进一个本地磁盘文件来储存的做法(除了少数大区块以单独的mcc文件存储),而不是一个区块简单对应一个文件。服务端想要知道一个区块位于哪个大region也很简单,直接对xz坐标进行移位操作即可。(如图所示)
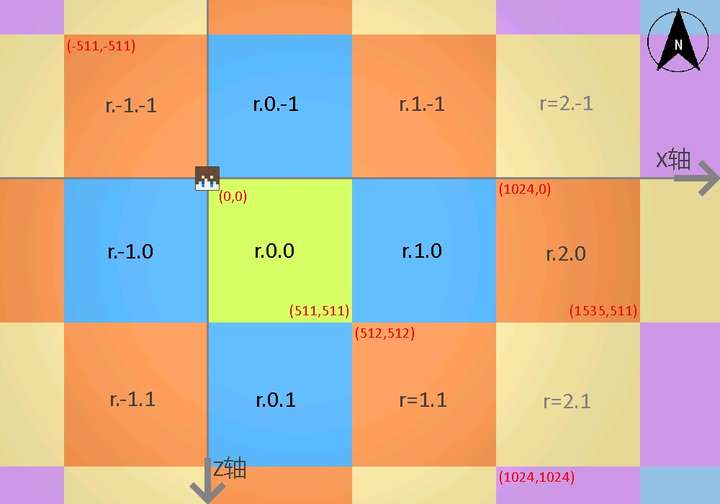
机械硬盘时代,这种做法可以尽量保持相邻区块都在同个本地文件中,从而减少寻道时间,降低磁盘I/O开销,较好地体现了计算机系统中的局部性原理。32这个数字应该是mojang在CPU、内存、磁盘三者之间权衡的一个选择了吧。
1.2 地表构造粒度细化
Minecraft 1.13之后的地形生成模块运行在独立的服务端线程中。
有了高度图,我们就可以据此生成地表了。新版本生成地表的工具便是地表构造器。
[注意] 地表构造器(ISurfaceBuilder)的Builder跟通常的Builder不同,它本身就是功能性的一个类,这个Build指的是地形的构造,而不是对象的构造
地表构造器就是原来的Biome#genTerrainBlocks,独立出来之后,它变得更加灵活、复用性更强。
而地表构造器配置提供至少两个信息,即顶层(top)方块和中层(middle)方块,比如在普通的平原生物群系,顶层(top)方块就是草方块,而中层方块则是泥土方块,此外还会有水底方块的信息(比如默认为砂砾)。
基岩的生成代码独立出来,而不是像过去一样包含在Biome#genTerrainBlocks的代码里,这也就意味着你不会因为不谨慎的覆盖而导致基岩的生成被“取消”了。
过去基岩的添加也是这个阶段所为。但是这其实是比较荒诞的,也就是,如果你覆盖了地表构造,就必须兼顾基岩生成。更加让人感到啼笑皆非的是,基岩生成是从 255 格开始向下判定 😅!现在基岩生成独立出来了,也不会从那么高就开始判断生成基岩了。
——摘自Yaossg’s site
1.3 缓存生物群系
每个区元生物群系只生成一次。在生成之后,每个区元的生物群系将会被缓存在区块的一个数组中。一个区块有多少个区元,就有多少个整数。注意这里仍然使用整数,而不是生物群系名字,在 1.18 之后才终于采用了与方块类似的调色盘来储存。
这样的缓存可以避免生物群系不断地生成,节省了不少的时间。但同时,又不得不向空间妥协——这样的缓存单位是区元而不是方块。
——摘自Yaossg’s site
注:这里的“区元”是香肠对概念”Area”的中文翻译,指的是生物群系生成的最小单位,不是Section(译作区段或子区块)。
1.4 缓存噪声生成器
minecraft的地形生成离不开噪声算法,大致流程:生成噪声(eg.柏林噪声、Simplex噪声)->放大化->插值(eg.Hermite三次插值)
Lithium模组使用了自带的快速缓存替代了未缓存的原版NoiseChunkGenerator,以提高区块生成性能。
2.数学运算
2.1 更换随机数生成算法
Java版在1.18更新之前,一直使用java内置的Random类获取随机数,用于生成噪声、地形插值等。
它基于LCG算法(线性同余)的改进版,使用CAS方式更新种子。在高并发环境下会大量自旋重试,导致性能降低。并且安全性比不上XorShift128+、MWC1616等算法(前者也被用于Chrome49浏览器及以上的V8引擎,以实现Math.random()。V8的神仙代码我实在不敢去翻)。
在种种原因影响下,1.18加入了新的随机数生成器Xoroshiro128++(也保留了原来的LCG生成器,在调用相关函数时可以额外传入一个布尔值来选择)。由于随机数在minecraft中的运用实在是过于广泛,此次更新会在各方面提升游戏整体性能,同时在一定程度上解决了不同种子生成相同地图的feature。(Mojang:这是特性,不是bug)
2.2 缩减正弦函数LUT大小
原版minecraft存储了一张从0到+2π的正弦函数表(Lookup Table,LUT),来加快三角函数计算。但是考虑到sin函数的对称性和平移性,其实只需要存储原表的1/4就够了。因此,Lithium作者将LUT从64K条目(256KB)减少到16K条目(64KB),使其能够更好地适应CPU缓存。
下面的代码展示了缩减版正弦表的生成以及Runtime期间对LUT的检验:
1 | |
但这也是有代价的:对于超出上述范围的参数,在查阅其值时则需要进行转换,带来额外CPU开销。所以Lithium的实现经过了严格优化:既然LUT表的本质是一个整数索引的数组,与其使用一堆if语句来转换超出范围的参数,不如直接对其进行位运算来达到转换效果,这样能够尽可能避免执行时出现branch,降低分支预测失败的额外开销。
1 | |
2.3 一些杂项
- Lithium对工具类
net.minecraft.util.math.Direction的内联覆写优化:原版Direction对象的offset向量存储在它所包含的另一个对象中,Lithium则将其内联,减少了额外实例化一个类的开销,并且更有利于JVM进行优化。 net.minecraft.util.math.BlockPos同上。Lithium的实现中还有很多上述优化,不再一一列举。作者对此的表述是:…makes a very small improvement to the generated machine code, but it seems worthwhile enough given how simple the implementation is…
虽然这些改动对生成的机器码的性能提升很小,但是考虑到实现它们是如此简单,这看起来足够值得…
最后,我个人还是建议在配置文件里关掉这些inline相关优化。毕竟它们带来的性能提升非常有限(特别是在GC已经炉火纯青的新版JVM中),玩家几乎无感,同时带来大量的inject和mixin操作又会拖慢启动阶段速度。
3.光照与渲染
3.1 光照计算
光照等级可以说是minecraft中一个老生常谈的问题了。农作物生长、生物生成等都会受到光照等级影响。请注意,这里所述的光照等级仅仅是游戏的内部数值,用来进行游戏机制判定和间接指导渲染,不等同于玩家直接在屏幕上所见的亮度,也不会在玩家更换光影、改变画面亮度等的时候重新计算。下图就是光照异常的一个实例,相信玩家们都曾遇到过。
对于原版光照引擎的调试过于复杂,简直就是一团乱麻,以至于所有尝试勇攀高峰的勇士最后都不得不感叹这屎山之高,最后选择放弃。实际上,在原版代码的基础上优化光照引擎就是天方夜谭——不如推倒重写。
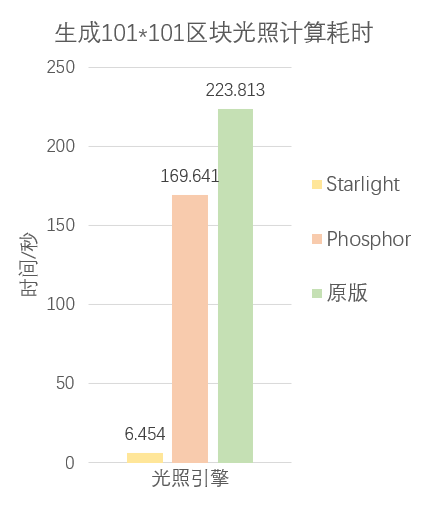
在这一背景下,由Tuinity作者 Leaf 开发的光照优化模组Starlight应运而生,对原版mc的光照代码进行了完整的重写。下面是在i7-8750H上执行单线程区块预渲染的耗时统计图,数据来自于curseforge。
重写后的光照引擎核心文件位于github仓库/src/main/java/ca/spottedleaf/starlight/common/light/StarLightEngine.java下。BlockStarLightEngine和SkyStarLightEngine都派生自StarLightEngine这一抽象基类。
经过几天的技术细节文献查阅和源代码翻阅,我大致摸清楚了starlight的优化思路:
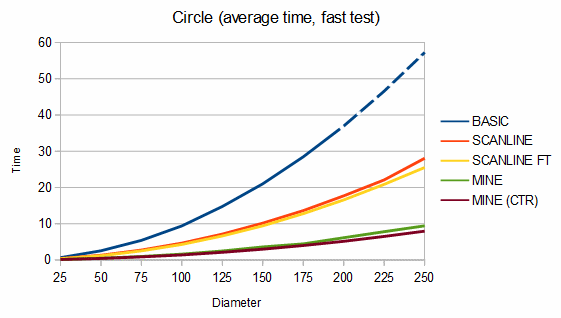
使用改良的flood-fill算法。各位还记得学算法时的经典例题—农田里的水池吗?Minecraft正是使用了广度优先的flood-fill算法来计算光的扩散。StarLight针对该算法在速度和浅递归深度上进行了优化,并且不需要任何基于堆的内存分配。它将始终填充矩形而不进行任何递归,并且可以根据初始点填充凸形和凹形而不进行递归。在特定场景下(fast test)比传统扫描线方法更快。给张图参考一下:
参考文章1(无需梯子,全英文):A_More_Efficient_Flood_Fill
参考文章2(需要梯子,全英文):fast-flood-fill-lighting-in-a-blocky-voxel-game-pt-1
内建了高性能
SWMRNibbleArray工具类(SWMRNibbleArray是mod开发者在代码中对Single Writer Multi Reader Nibble Array的简写命名),支持写时复制策略(COW),可以提高并行操作性能。减少光照更新队列的计算任务数。因为Minecraft在计算天空光照和多方块光照的叠加时都是利用
Math.max()取的最大值,而不是对它们求和,因此,在亮度传递过程中对-x, +x, -y, +y, -z, +z六个直接相邻Block执行亮度检查,若其亮度大于中心方块目标亮度,则执行短路逻辑,不将该方块提交至亮度更新队列,进而降低运算量(尤其是对getLightLevel()和getState()的调用数量可以缩减6倍)。简化后的代码如下:
1 | |
- 方块的碰撞检测优化。通过在
QueueEntry中增加有关是否计算碰撞的字段,减少了大量不必要的碰撞体积计算。 - 相较于原版的
LongLinkedOpenHashSet,Starlight使用基于数组的FIFO队列存放更新任务,无需额外的hash查找。(但是得到性能提升的同时也失去了取消等待中的光照更新的能力) - 与原版相比,Starlight不是从上到下迭代读取方块,而是使用存储在子区块(section)上的bitset来记录哪些块的opacity为0。因此,它可以确定并使用高度图来设置光源。这种做法可以使用最小数量的方块获取来初始化区块中的天空光源。
总之,Starlight对minecraft的光照引擎进行了完全覆写,带来了极大的性能提升,同时也会带来一点不稳定因素(现在还是beta版本)和兼容性问题。但这并不妨碍它成为一款相当优秀的优化模组。Mojang在java版1.20参考Starlight改进了原版光照引擎,虽然性能仍不及Starlight,但Starlight在客户端依然被淘汰,作者也不再继续发布后续更新。
4.游戏机制
4.1 优化爆炸
材质包:方块概念")
提到爆炸,还得从它的基础实现说起。在原版minecraft1.12.2中,当我们手持打火石点燃TNT时,以下事情会依次发生:
- 游戏在原位置上生成实体TNT,初始化剩余时间(TNT默认为80 ticks);原位置的TNT方块立即消失
- 每Tick更新该TNT爆炸剩余时间,直至到达0
- 随后实例化一个
Explosion对象,开始执行爆炸相关逻辑 - 阶段A:计算受影响的方块,将其储存到ArrayList字段
affectedBlockPositions内;通过getEntitiesWithinAABBExcludingEntity获取爆炸范围内的实体,对其赋予伤害和冲击动量 - 阶段B:激活爆炸音效、粒子效果,计算掉落物,触发
onBlockExploded,放置火焰(如果要求放置火焰的话)。注意Block.onBlockExploded事件是在阶段B触发的,也就是说阶段A不会对方块造成实质性损毁
爆炸的计算过程非常直观。从爆炸中心近乎均匀地释放出1352条冲击波射线(与物理学中的电场线类似,它们是假想出来的,并非客观存在,无法在游戏中直接观测),每条射线给定一个初始能量值,遇到方块(包括空气)会出现能量衰减,并且衰减值与遇到的方块的爆炸抗性等因素有关。直到该射线的能量衰减到零或负,停止传播。对这1352条线依次运用以上方法即可计算出所有需要被移除的方块了。如下图所示:

如果某个爆炸具有附带火焰的效果(如地狱炸床、末地水晶爆炸等createFire字段为true的爆炸),那么游戏还会检查遇到的每个空气方块的底部是否为非透明方块,若是,则按照指定概率在该固体方块上生成火焰。然而目前minecraft中很多爆炸其实是不生成火焰的,比如TNT爆炸。因此我们在处理这类爆炸时就不用尝试在所有遇到的空气方块底部生成火焰了,可以直接跳过。这无疑减少了BlockPos对象的分配和getBlockState()的调用:
1 | |
在模拟爆炸射线传播时,每束射线在每次迭代只传播0.3个方块,因此尤其是在射线密集的时候会导致大量相同位置的方块被重复计算,这是对CPU算力的一种浪费。Lithium增加了一层针对同方块的检测,若performRayCast() 连续多次对同一方块调用traverseBlock()以获取resistance,则直接会复用先前的结果,无需再算。
1 | |
不仅如此,Lithium还将原版collectBlocksAndDamageEntities()方法重定向到自己基于LongOpenHashSet作为爆炸摧毁方块集合的实现。使用整数代替(即压缩)对象来表示方块位置,避免了BlockPos对象的分配进而减少内存占用、减轻GC压力。但压缩/解压过程会略微增加cpu负担,属于之前章节2.3里面提到的“CPU换内存”优化行为。
4.2 优化漏斗
众所周知,漏斗是一种比较容易引起性能问题的红石元件,可以被用于卡服务器。漏斗自带的TileEntity每Tick都会更新,每隔8 Ticks尝试传送物品。漏斗传送物品由updateHopper()实现,其核心实现代码如下:(已经被我适度简化)
1 | |
从updateHopper()的代码可以看出漏斗是如何进行物品传送的:Minecraft服务端首先检查漏斗的开启状态(比较违反直觉的是,被红石信号激活的漏斗处于关闭状态),若漏斗内容物非空,则尝输出一个内容物;若漏斗内容物非满,则尝试从连接到漏斗的容器中拉取一个物品,或者尝试捕获漏斗上方的掉落物。只要上述两个操作中的一个执行成功,漏斗就会标记所在区块为脏区块(或者称为“已修改区块”,这种机制确保了更新后的方块实体能够保存到硬盘上),并把下一次尝试推迟到8 Ticks之后;然而,如果上述两个操作都没成功,那么漏斗将会在每Tick都重新尝试调用updateHopper。这为漏斗的性能劣化埋下了种子。
首先,若漏斗内容物非空,则尝输出一个内容物。游戏先检查目标容器是否已满,这个检查过程是通过遍历目标容器实现的,在最坏的情况下,如果目标容器已满,游戏需要遍历其中的每一个stack。之后遍历漏斗内容物的所有stack,对遍历到的stack,尝试取出一个物品,输出到目标容器,这个遍历过程直到上述操作成功才停止。由于输出过程会先去修改漏斗内容物(无论输出是否成功),再尝试输出,如果输出失败,这意味着游戏还需要把原来的内容物Inventory提前复制一份,并且在失败时根据这个备份Inventory恢复原样。这种低效且离谱的处理逻辑和滥用的遍历是导致漏斗卡顿的重要原因。
随后,若漏斗内容物非满,则尝试从连接到漏斗的容器中拉取一个物品,或者尝试捕获漏斗上方的掉落物。与第一步大同小异,这里不再赘述。
最后,漏斗调用基类提供的markDirty()来标记方块实体所在区块为脏区块,这个方法做了两件事:将漏斗所在区块的dirty标志位修改为true、更新比较器的输出等级。前者只涉及赋值运算,开销较小;后者的具体实现在updateComparatorOutputLevel内,执行流程参见我写的注释:
1 | |
为了实现更新,需要枚举不同的朝向,遍历各个朝向所指的第一个方块,我称之为“后继方块”。后继方块被通知NeighborChange(在1.12版本中就是我们常说的“方块更新”,在1.13之后方块更新机制发生了比较大的变化,有了专门的“比较器更新”,也算是官方采取的性能优化措施吧)之后,若后继方块为实体方块,则继续朝着枚举方向再偏移一格,得到的方块我称之为“再继方块”,如果再继方块应当在WeakChanges发生之后被通知,则进行通知。
写到这里,似乎看不出这个函数与比较器有什么关系,不过别着急,这是因为在目前所有的Minecraft方块中,只有红石比较器能够响应WeakChanges(由于我手上只有一套1.12.2的源码,所以上述说法截止至Minecraft1.12.2)。

不难看出,updateComparatorOutputLevel的性能开销比前者大得多,不仅可以触发周围多个方块更新,而且涉及诸多对象的内存分配,对CPU和内存都不够友好。
mojang的代码是如此的烂,我们要怎么优化呢?BetterFPS和Lithium这两个性能优化模组向玩家们交出了满意的答卷:
- 优化掉落物的拾取:Lithium实现了一个“实体追踪引擎”,每个entity section(大小为16x16x16 blocks)存储了这个区域内所有掉落物(视为一个整体)的最后一次变更时间戳(坐标改变、存在性改变、NBT数据改变等)。漏斗利用这个变更时间戳,结合先前的拾取结果,可以很方便的判断自己的拾取区域内的情况。举个例子,如果漏斗在上一次拾取掉落物尝试失败(或者根本就不存在掉落物),并且根据变更时间戳判断得出这一次没有任何掉落物状态改变,那么就可以推断出这一次拾取掉落物一定会失败,完全可以跳过这次的掉落物拾取尝试,省掉不少麻烦。
- 缓存漏斗内容物:BetterFPS和Lithium都对漏斗的内容物进行缓存,并且使用计数器来管理缓存版本。原版漏斗每次更新都会调用
getInventoryAtPosition()这个耗时较长的全局查询方法来获取漏斗的内容物,缓存Inventory能够有效减少这类方法的调用,避免其成为性能瓶颈。 - 分等级缓存漏斗所连接的外部容器:Lithium将漏斗所连接的容器(输入和输出)分为五个等级进行缓存,这种灵活的缓存方式能够用最小的代价去还原原版漏斗的行为,在尽可能不影响游戏逻辑的情况下作出最大的优化。
1 | |
参照上面的代码,UNKNOWN代表没有任何信息被缓存,这也是漏斗创建之后的初始态;BLOCK_STATE适用于外部容器不是方块实体的情况(比如堆肥桶);BLOCK_ENTITY与REMOVAL_TRACKING_BLOCK_ENTITY都适用于方块实体容器,如果外部容器是InventoryChangeTracker的实例(换句话说,容器的变更可以被Lithium追踪到),那么该容器对应的缓存等级就为REMOVAL_TRACKING_BLOCK_ENTITY;NO_BLOCK_INVENTORY表示不参与整个漏斗作用过程的方块。
- 休眠机制:Lithium引入了休眠机制,漏斗、熔炉、篝火等需要实时计算的方块能够休眠,降低其性能开销。Lithium采用“发布-订阅”模型(我上一次接触这个模型,还是在阅读Vue的响应性系统源码的时候),漏斗(订阅者)接收实体追踪引擎和输入输出容器(发布者)的消息,进而唤醒休眠状态的漏斗。这些消息一般与实体状态变更、容器状态变更有关,提醒漏斗该更新缓存了。
- 重写物品传输逻辑:原版逻辑是无论能否传递成功,都要先复制一份stack副本,再尝试传输。Lithium重写了相关代码,把逻辑理顺,避免了传输失败情况下的stack复制。
考虑到漏斗矿车的行为和所处环境等因素都比普通的漏斗方块更复杂、更难预料,Lithium没有给漏斗矿车加缓存。
4.3 优化信标
4.3.1 缩减信标计算量
信标每80 Ticks更新光束特效、赋予玩家药水效果。在更新光束前,需要进行完整性检查(以确保满足射出光线的条件),检查内容包括:信标上方是否被遮挡、信标塔是否完整。信标塔的完整性检查使用三个嵌套的for循环实现:
1 | |
BetterFPS对信标塔的完整性检查作出了两处优化:
- 原版Minecraft在发现方块不能构成金字塔之后,由于break语句只能退出第三层循环,无法及时退出全部循环,浪费算力。BetterFPS优化了执行逻辑,给最外层for循环加上标签,使得循环可以立即退出。
- 上述信标塔完整性判断逻辑所属的函数在服务端和客户端均需要执行,但是两端的需求不同:服务端需要计算出具体的金字塔高度等级,以便执行其他依赖于金字塔高度等级的游戏逻辑(比如药水效果的更新);而客户端的事情仅限于判断光束是否满足射出条件,来决定是否渲染光束,不需要知道金字塔具体的高度等级。因此,BetterFPS对两端的需求差异做出了针对性的优化,大大减少了客户端的计算量。(具体来说,客户端只需判断两个主要条件:①金字塔的组成方块是否满足最基本的3行×3列×1层的构型;②信标上方是否无遮挡。若满足条件①,那么可以断言这个金字塔等级一定有效,且大于或等于1,不用再继续往下层判断;若①②同时满足,那么光束一定可以射出。)
4.3.2 移除信标光束透明层
玩家搭建信标后,游戏会渲染出信标的光束。这道光束本身并不是一个实体,而是直接调用OpenGL画出来的,其分为内外两层:内层为不透明层,且随着时间(partialTicks)的流逝而不断绕y轴旋转;外层为透明层,且不会随着时间旋转。

BetterFPS可以移除信标光束的透明层,使得游戏在渲染信标光束的时候,GlStateManager和顶点缓冲的操作次数几乎减半。在信标数量较少的情况下,FPS提升微不足道,但是在信标密集的时候可能有用。
5.底层基础
JVM就像一个神奇的黑盒,为程序员隐藏了大量底层细节。在JVM层面做优化,不修改上层代码就可以提升minecraft的整体性能,这给我们带来了另一种优化思路。
5.1 JVM的选择
大多数minecraft玩家的JVM选择有:Hotspot,OpenJ9,DragonWell。其中Hotspot是默认项,因此也是绝对的主流。
这篇发表在mcbbs上的文章详细介绍了作者对不同JVM的性能测试结果:换个 JVM,最高节省43.3%内存,提高36.9%CPU效率。
作者以mspt(Millisecond Per Tick,每刻运行所需毫秒数)作为衡量CPU性能的标准,下面我尝试简要概括一下这篇文章的测试结果:
- Hotspot的CPU效率较高,但是内存占用相对其他JVM而言较大
- OpenJ9在降低内存占用方面表现突出,但是CPU效率不理想,表现为mspt在不同场景下平均上升了约30%
- Azul Zulu的CPU效率在所有参与测试的JVM中最高,表现为单玩家mspt降低约20%,内存占用也较Hotspot低
- DragonWell有着和OpenJ9相仿的低内存占用,CPU效率较高,仅次于Azul Zulu
DragonWell和Azul Zulu在上述测试中表现可圈可点,我们根据自己机器的CPU和内存情况可以很容易作出最佳选择。Hotspot兼容性较好,并且附带环境比较完整;目前已知OpenJ9和DragonWell不附带JavaFX,需要额外配置才能启动HMCL的用户界面。我在早期还听说过一个叫做Azul Zing的JVM,在Linux服务器上搭配ReadyNow进行热点代码的预编译、开启透明大页提升内存性能(内存紧张时减少缺页中断)后,只要其他配置妥当,也可以有不错的体验。
我自己也在今年寒假做过测试,启动minecraft1.12.2客户端+服务端(带forge、模组、光影):
| 客户端FPS(最高/最低) | 刚进入地图后游戏进程内存占用(MB) | 稳定后游戏进程内存占用(MB) | 启动时间(Sec) | |
|---|---|---|---|---|
| Hotspot | 63/137 | 3332 | 3032 | 47.96 |
| OpenJ9 | 54/95 | 1236 | 963 | 54.28 |
| DragonWell | 55/115 | 3297 | 1836 | 50.43 |
由于我测试的是FPS,上文测的是mspt,因此测试结果和上面文章并不冲突。
5.2 JVM参数调优
网上有许多大神给出了调优的JVM参数,这些JVM参数相较于启动器默认值而言,差异主要在于:
- 更换垃圾收集器。一般是开启G1。其实JDK1.7就已经引入G1了,但是JDK1.9以上才默认开启。G1在标记对象的过程中只有Initial Mark和Final Mark阶段需要进行STW,其余阶段均与游戏程序并发,对现代多核CPU更加友好。
- 调整GC分代策略。在传统的分代回收算法下(例如开启
-XX:+UseConcMarkSweepGC -XX:+UseParNewGC),由于老年代对象的回收开销更大,增加-XX:+UseAdaptiveGCBoundary有助于减少新生代对象漏到老年代的机会,降低老年代GC压力。 - 调整GC停顿时长。 我看到的优化参数中出现最多的就是
-XX:MaxGCPauseMillis=50设置GC最大停顿时长为50ms(刚好是一个游戏刻的时间长度),让卡顿更不容易被玩家感知。若设置得太小,那么GC就会频繁触发(甚至全量GC),考虑到GC触发的时候停止游戏线程和启动GC都需要额外的资源开销,频繁的小GC会对程序吞吐量造成一定负面影响,因此不建议将这个值设置过小。 - 核心库优化。例如针对Java中的string操作,我们有
-XX:+OptimizeStringConcat和-XX:+UseStringDeduplication等参数。 - 运行时优化。例如
-XX:MaxInlineLevel设置最大函数内联层数,函数内联的优点缺点都很突出,可以根据游戏平台的实际性能作出权衡;-XX:-DontCompileHugeMethods也同理:超过设定阈值大小的代码,即使被探测成为热点代码,也只会被解释执行,永远不会被JIT编译到机器码;-XX:-OmitStackTraceInFastThrow开启后部分错误将得不到堆栈追踪信息,使得游戏代码中异常处理的代价更小,但是不利于玩家调试minecraft(讲一件真事:比如游戏初始化LWJGL音频模块时,找不到OpenAL64.dll,若加了这个参数,那么日志输出里面只会显示“Unable to initialize OpenAL. Probable cause: OpenAL not supported.”,不会提示你刚刚出错地方的调用栈,你也很难推断出真正原因是OpenAL64.dll缺失)。











