使用腾讯云COS搭配CodingCI搭建个人网站

使用腾讯云COS搭配CodingCI搭建个人网站
gy1 总述
最近我对个人网站进行了一次比较大的改变,将其从gitee迁移到了腾讯云,并且注册了独立的域名,这意味着我不再依赖于gitee,有了更大的自主权,基本上摆脱了以往寄人篱下的状态了。新网站使用腾讯云COS搭配CodingCI搭建,腾讯云COS是一种对象存储服务,可以帮助我管理网站的静态资源,而CodingCI是一个持续集成工具,我用来自动化构建、测试和部署网站。这次迁移并不仅仅是技术上的一次迁移,更是一次有益的尝试,也让我变得更加迷茫。这算是比较新的一种建站思路,遂记录之。
下面是我搭建网站的流程:
- 腾讯云-域名购买和备案
- Gitee-创建项目仓库,存放需要构建的代码
- 腾讯云-使用对象存储服务,初始化存储桶
- Coding-选择合适的Docker容器,配置CI工作流
- DNSPod-配置域名解析
- 腾讯云-SSL证书签发
- 接入Algolia搜索服务
- 接入百度统计
- 搜索引擎收录(尚未完成)
这篇文章主要记录Coding平台和腾讯云对象存储的使用,其他步骤省略不提。
2 腾讯云COS搭建与配置
2.1 搭建存储桶
创建一个存储桶,将权限设置为公有读私有写;地域设置为中国香港(或者其他非中国大陆地区),既能确保较好的访问体验,也充分考虑了法规和政策的合规性,避免不必要的ICP备案麻烦。
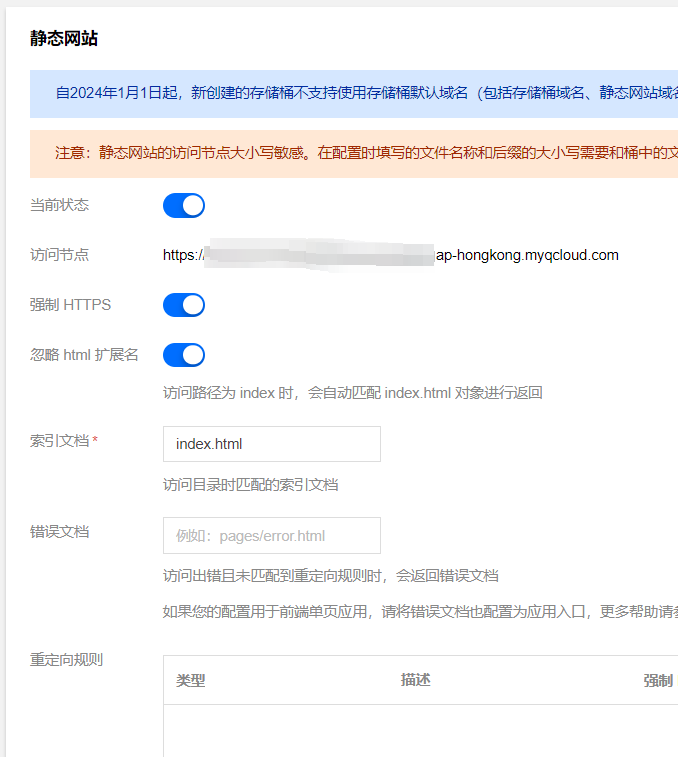
在腾讯云COS控制台,点击侧边栏基础配置-静态网站,启用静态网站访问。开启“忽略html扩展名”,填写“索引文档”为“index.html”。建议开启强制Https,只需要后期申请SSL证书即可。
2.2 网络安全
2.2.1 配置告警策略
对存储桶的响应状态码和外网流量,配置告警策略,并且结合有效的通知手段(微信+短信+邮箱),尽可能让恶意刷流量等行为在第一时间被感知。

Note:腾讯云的对象存储不支持手动调整QPS限制。需要注意监控系统的请求量。
2.2.2 配置防盗链
2.2.3 拒绝解析境外IP
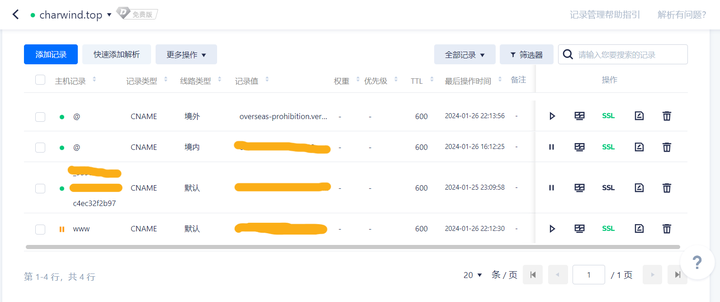
网站初次上线之后,我在百度统计平台发现有大量境外IP来访,并且这些IP都有着明显的机器人特征(这些特征包括但不限于:访问时长均为2分钟整、除了网站首页之外没有访问任何其他的页面)。有一点让我比较疑惑:虽说百度统计支持智能屏蔽数据,但是这些明显异常的访问数据并没有被百度屏蔽掉。
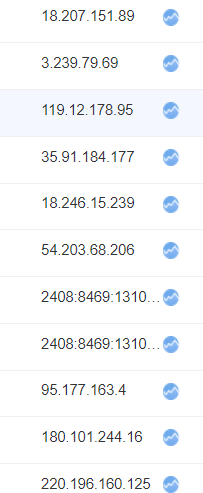
为了节约服务器流量,并且考虑到我的网站基本上不面向外国访客、没有境外IP访问的需求,所以我打算在DNS层面处理,将境外IP全部解析出去,同时保留境内IP的正常访问。在DNSPod上修改现有CNAME记录的线路类型即可解决:
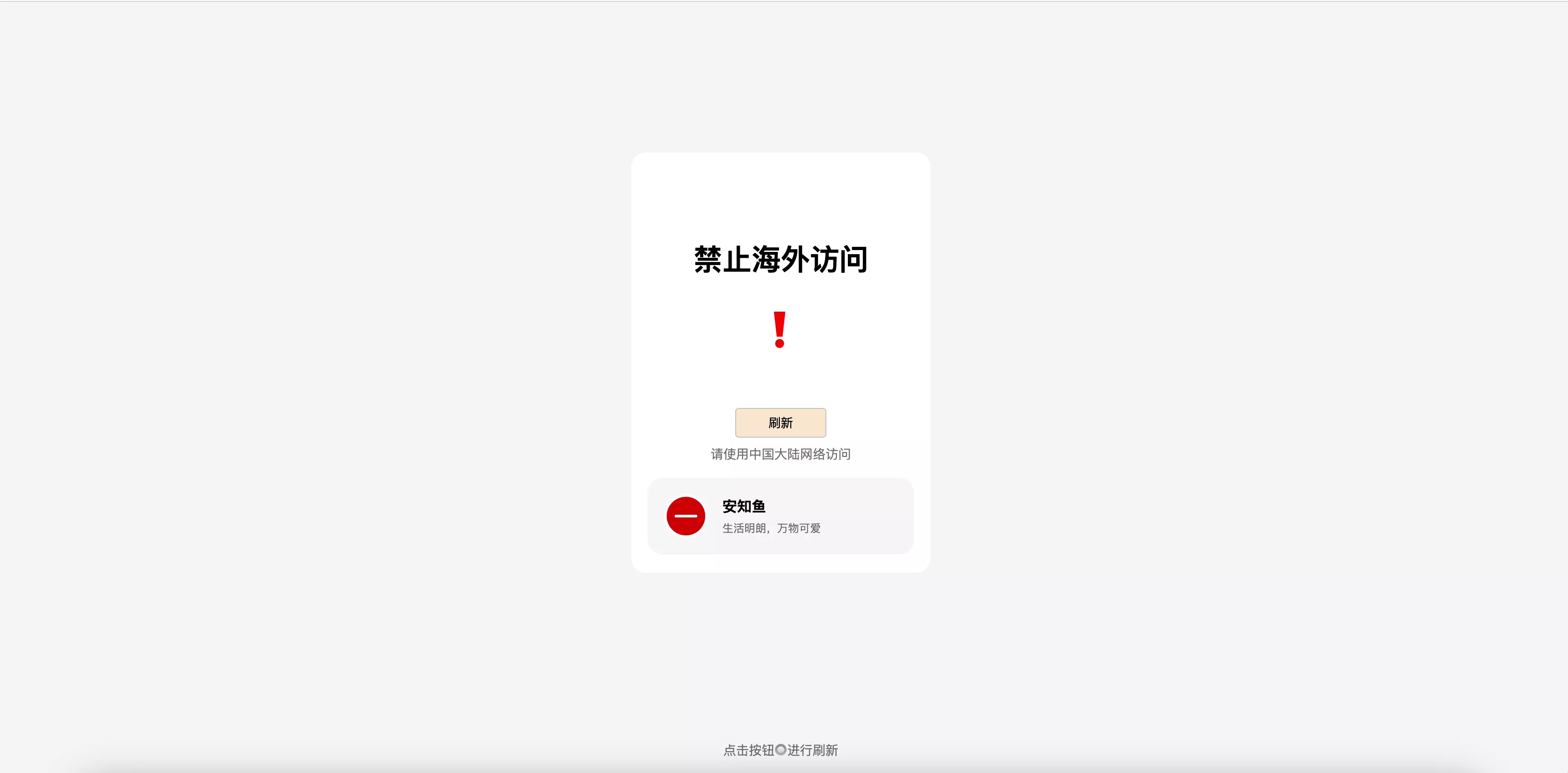
在解析层面处理,将境外IP全部解析到如下的导流页面(基于Vercel,由第三方实现,不影响我的主站流量):
2.2.4 准备好紧急预案
对于网站运行中出现的突发情况(比如受到网络攻击、不幸被GFW拦截),准备好紧急预案,提供一套有序、有效的应对措施,做到自己心里有数,最大程度减少损失和危害。
对于网站运行中出现的可预知情况(比如SSL证书到期、域名需要续费、腾讯云COS资源包需要续费),提前做好及时的提醒和日程管理,免得自己搞忘。
2.2.5 启用日志
启用日志管理后,COS的所有访问请求信息都将以日志的形式,以5分钟为单位保存至目标存储桶中,增强存储桶操作的可追溯性。
3 使用Coding持续集成
3.1 Coding简介
CODING 是腾讯云旗下一站式 DevOps 研发管理平台,围绕 DevOps 理念向广大开发者及企业研发团队提供代码托管、项目协同、测试管理、持续集成、制品库、持续部署、云原生应用管理 Orbit、团队知识库等系列工具产品;提供 SaaS 模式或私有部署模式。
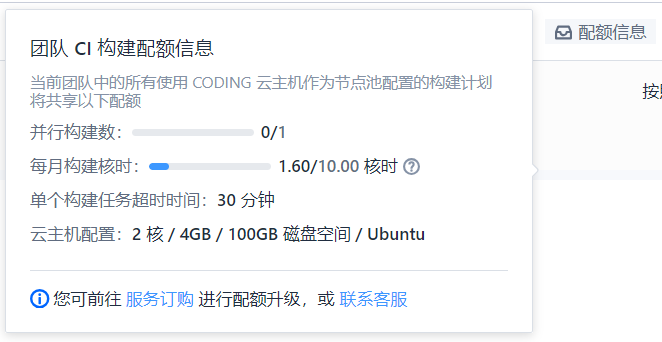
我使用Coding提供的持续集成来自动化构建和部署网站。Coding对免费用户提供了2核4G的Ubuntu云主机,每月有10核时的构建时间,另有100GB的磁盘空间(Coding平台持续集成的CPU核数不支持调整。如需调整CPU核数,建议使用更灵活的云原生构建)。Coding提供的免费资源对于目前的我来说已经完全够用。
3.2 CI初始化
创建项目之后,右侧边栏持续集成-构建计划-创建构建计划-选择构建计划模板,点击右上角的自定义构建过程(不建议使用官方提供的Nodejs + Express + Docker模板)。填写信息后,进入配置页面:
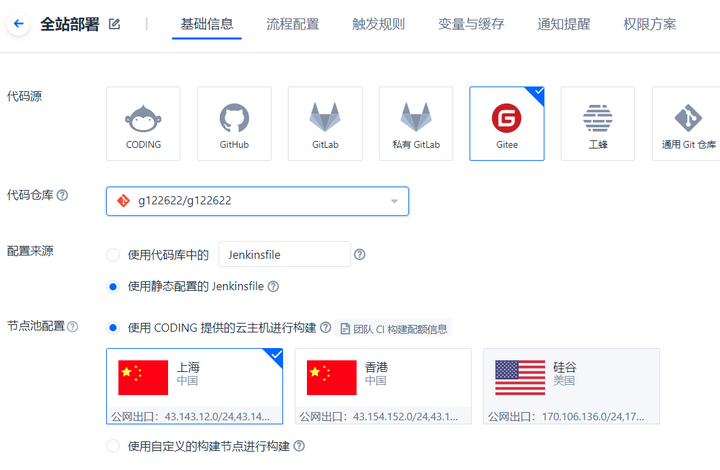
’代码源’由你的仓库位置决定,因为我使用gitee来托管待构建的源码,所以这里我把代码源设置为gitee。选择代码仓库并且配置完毕节点池之后,开始进行流程配置。
3.3 CI配置
Coding的CI是基于Jenkins实现的,其配置文件遵循Jenkinsfile格式。下面给出我的CI流程配置:
1 | |
- 检出步骤:官方已经默认给出,我也没有进行更改。
- 构建步骤:需要NodeJS环境,然而默认构建环境的NodeJS版本太旧(v10),远低于Hexo5需要的v16。为了指定更高的NodeJS版本,需要手动选取合适的Docker镜像,我在这里选取的是NodeJS v19。
- 开始构建,执行npm install。我在package.json中指定了postinstall脚本,在安装依赖完成之后,我指定的脚本会被自动调用,构建即可自动开始,不用在Jenkinsfile里面写任何构建逻辑。
- 最后把构建产物(hexo的构建产物在public目录)上传到腾讯云COS,使用coscmd工具进行上传(需要pip install)。
Note:区分下面这两个coscmd命令:
coscmd upload -r ./public / 将public文件夹本身连同内容上传到根目录,目录级数增加一级;
coscmd upload -r ./public/ / 将public文件夹的内容(不包括public文件夹本身)上传到根目录,目录级数不变。
第一个命令中的./public没有斜杠结尾。
配置过程使用了环境变量,用来存储一些有关腾讯云API的信息,注意保密。
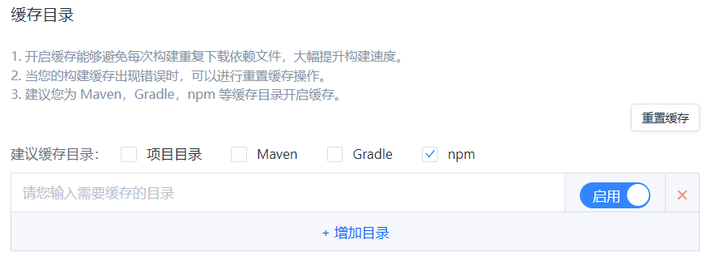
3.4 使用缓存加速构建
开启缓存能够避免每次构建重复下载依赖文件,大幅提升构建速度。在变量与缓存选项卡,勾选缓存目录为npm:
3.5 触发规则配置
切换到触发规则选项卡,启用代码源触发-代码更新时自动执行,自行配置触发规则,代码源中同时满足设定规则的代码提交将会触发流水线。
一切配置完成之后,在gitee提交代码即可触发自动构建:
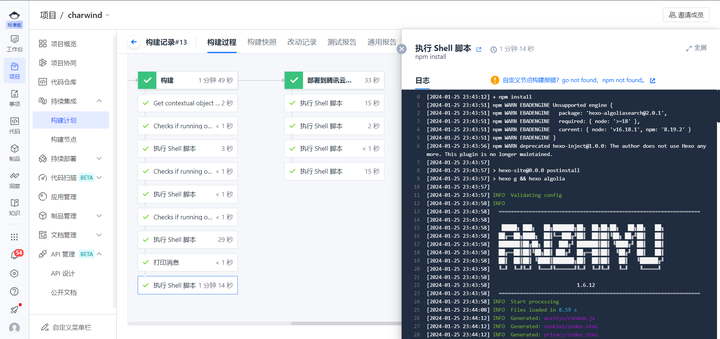
构建过程以流程图展示,并且能够看到服务端的实时日志输出:
4 云监控+COS SDK实现异常负载下的自动封堵
4.1 为什么要做自动封堵?
存储桶设为公有读取的一大弊端就是容易被恶意刷流量,可能造成巨大资金损失。目前已经见到大量个人网站因存储桶被盗刷而欠费上千甚至上万元的不幸案例。然而腾讯云官方提供的防盗刷机制聊胜于无,起不到太多的正面作用。下面介绍一下我是如何使用云监控+COS SDK实现异常负载下的自动封堵的。
4.2 Plan A
调用腾讯云可观测平台提供的GetMonitorData接口拉取COS实例的监控数据。每个主账号每月有100万次免费请求额度,对我来说已经完全够用。超过免费额度后如需继续调用接口需要开通 API请求按量付费。
统计时间遵循Timestamp ISO8601标准,示例值:2019-03-24T10:51:23+08:00
腾讯云提供的Serverless SCF内置了云监控SDK和COS SDK,我们可以使用其对GetMonitorData接口进行周期性的拉取,在拉取到统计数据之后,计算出单位时间内的流量,根据事先设定好的阈值判断是否将存储桶ACL设为private,这样就实现了异常负载下的自动封堵。
4.3 Plan B
但是SCF的计费方式非常不人性化,开通使用云函数三个月后的用户每月不再享受免费额度,系统每月会强制发放基础套餐额度,同时自动扣除12.8元(扣除方式为:每天扣除0.41元)(费用数据取自2024年2月3日)。所以我们还有Plan B:利用告警通知的接口回调机制,主动地唤起部署在Coding平台上的CI任务,以代替SCF被动的轮询机制。这里的CI任务负责将存储桶的操作权限设为私有读写,以完成存储桶的自动封堵。
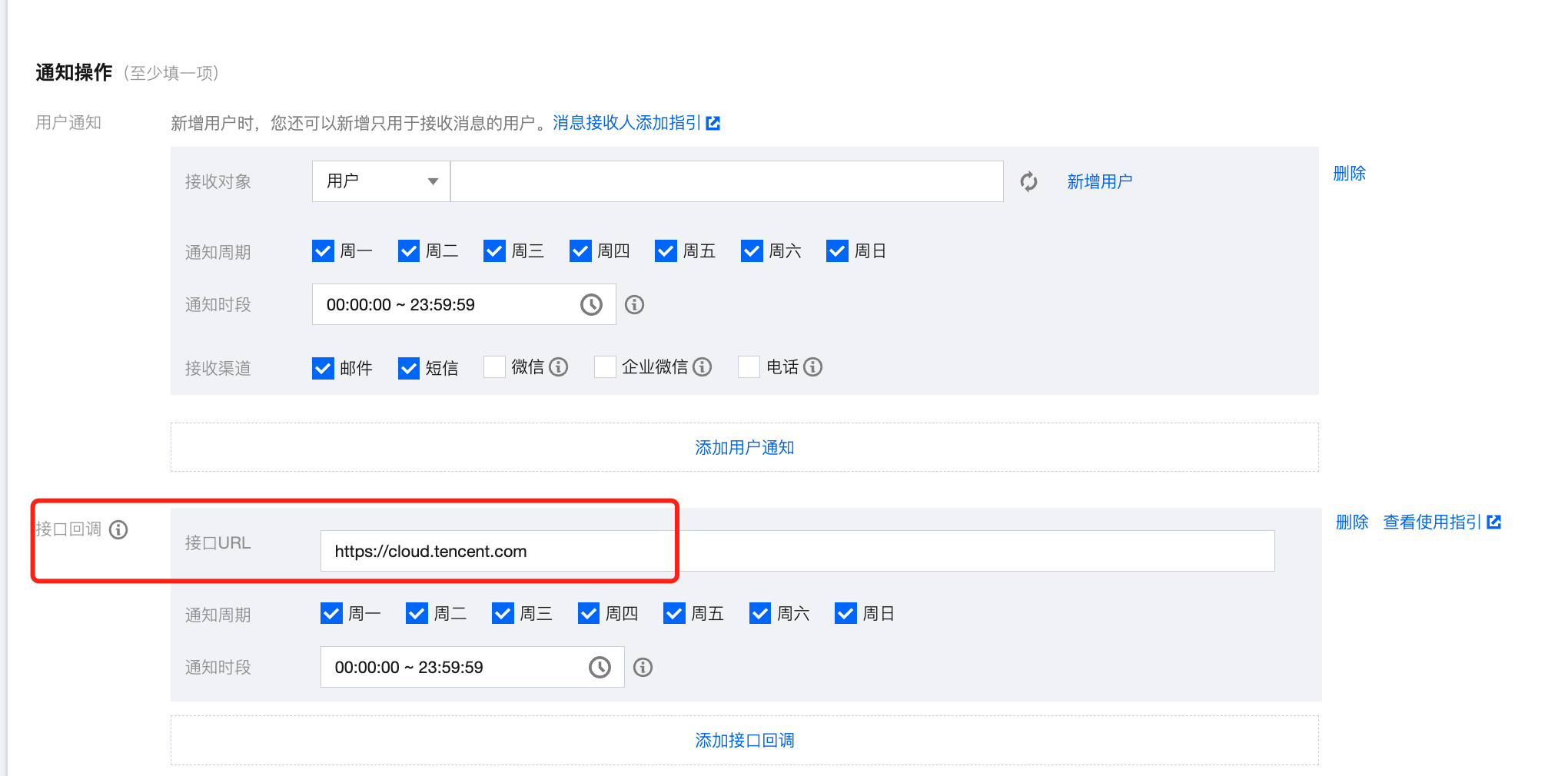
腾讯云告警接口回调和CODING持续集成API所使用的认证方式均为基于BasicAuth的用户安全验证,所以二者可以进行比较流畅的对接(然而事实告诉我,对接并不像我想象的那样顺利,后面会写)。先创建一个新的构建计划,触发规则设定为“API触发”,然后按照如下格式填写在腾讯云告警配置面板的“接口回调”里面:https://{用户名}:{令牌名称}@{TEAM_GK}.coding.net/api/cci/job/{JOB_ID}/trigger
其中用户名和令牌名称来自新建的Coding项目令牌。
随后配置项目的jenkinsfile。默认的Docker容器Node版本太低,无法满足cos sdk的最低版本要求,故这里依然选择官方提供的Node v16 Docker容器去运行脚本。
1 | |
handler.js要提前设置好Bucket、Region、SecretId、SecretKey四个环境变量,具体的设定方式见代码注释:
1 | |
4.4 遇到的问题
Coding的API接口要求请求时带上ref参数,然而腾讯云的接口回调不支持自定义请求body,这就导致了:虽然CI可以被触发,但是会因为“指定构建的版本不存在”而启动失败。提交工单和工程师协商之后,决定不使用代码仓库,直接从存储桶上拉取handler.js。
5 性能优化
5.1 使用ServiceWorker缓存静态资源
ServiceWorker生效后,第一次加载需要缓存的资源时,将其缓存到本地,下一次对缓存过的资源发起访问时,将直接从硬盘中读取而非从网络下载。本地缓存对用户二次访问的体验有较大的提升(提升程度取决于缓存的资源的数量以及其它相关的指标)。在旧访客比较多时,还可以极大程度地降低服务器地负载。此外,即使用户暂时没有网络连接,用户仍然可以浏览网站中已+经被缓存的资源,在没有网络的情况下获得良好的体验(适用于网络不稳定的移动端)。
我使用swpp-backends(以下简称 swpp),为网站生成一个高度可用的 ServiceWorker(以下简称 SW),以优化二次加载、提供离线体验、提高可靠性,并为此附带了一些其它的功能,例如预缓存、缓存增量更新、请求合并、URL 竞速、Request 篡改等等。
这里是Swpp Backends的官方文档:Swpp Backends 官方文档