【万字长文】一条坎坷的多线程优化之路--剖析Minecraft多线程发展史

【万字长文】一条坎坷的多线程优化之路--剖析Minecraft多线程发展史
gy游戏开发者只要好好写代码就可以,可是玩家要考虑的事情就很多了。
自诞生以来,Minecraft以其创新的玩法吸引了全球无数玩家,更是常年霸榜成为全球销量第一的游戏(Wikipedia)。然而,这款游戏始终面临着一个巨大的技术瓶颈:单线程。在多核处理器大行其道的当下,多核心带来的优势无法得到充分利用,“一核有难,多核围观”的调侃在各大论坛中不绝于耳。随着时间的推移,在多方共同努力下,Minecraft终于逐渐引入了一些多线程优化措施,尽管进展较慢、力度不大,却也实打实带来了一定的性能提升。

在这篇文章中,笔者将回顾Minecraft的多线程优化历程,从最初的单线程架构出发,探索游戏是如何逐步克服技术挑战,引入多线程机制的(尽管这种多线程机制并没有显著提升游戏体验)。笔者还会试着剖析Minecraft为何难以实现全面的多线程化,以及第三方服务端的开发者们是如何引入力度更大的多线程机制来改善游戏体验的。
建议前往我的博客阅读本文,以获得更好的markdown阅读体验,以及更加清晰的图表。
声明:
- 本文为作者原创,笔者通过大量阅读不同版本的Minecraft游戏代码才撰写出本文,创作不易,请勿转载。文中不乏疏漏之处,敬请批评指正。
- 本文中出现的所有Minecraft代码仅供学习交流使用,取自Java版
1.12.2,1.14.4,1.16.5,1.18.2等版本,使用官方或非官方(mcp)提供的映射表反编译而来,所有源码在反编译的基础上已经过本人的适度修改,以确保和原版代码不同。(1.14.4和1.18.2采用的反编译工具链是CFR 0.152,使用Microsoft提供的mapping)
0 前置知识
0.1 Minecraft有哪些线程?
作为开篇,我们首先来看看Minecraft究竟有哪些线程。
通过阅读源码分析Minecraft的启动过程,并结合VisualVM这一调试工具,我们可以梳理出Minecraft的一些主要线程的运行时间线,如下图所示。

从图中可以看出,Minecraft 1.12 的线程结构非常单一,大量的操作都没有实现并行化。客户端主线程Client thread负责游戏初始化、处理UI交互、启动其他线程等工作;而在服务端,Server thread则是执行主要游戏逻辑的核心线程,几乎所有耗时的运算都由这一个线程承担(实体更新、世界生成、光照计算、随机刻等)。虽说有辅助线程(如Chunk Batcher、Netty网络线程、文件IO线程)承担其他任务,但是并没有真正减轻服务端主线程的负载,在调试工具VisualVM中也不难发现,这些辅助线程长期处于空闲状态。

所以,虽然早期版本的Minecraft看起来不止一个线程,但它本质上仍然是一个单线程游戏,主要游戏逻辑都集中在服务端线程中。除非对整个游戏架构(甚至是游戏机制和规则)进行根本性的改变,否则Minecraft很难实现真正的多线程化。
注:
- 这张示意图基于Minecraft1.12.2单机游戏模式绘制,并附带forge环境,但并未加载任何mod。
- 图中出现的方法名和类名,使用MCP提供的映射表获得。
- 图中省略了由JVM自动创建的线程,如
RMI TCP Accept,Signal Dispatcher,Attach Listener。Minecraft的源码也没有对这些线程进行显式干预。
值得注意的是,区块渲染线程不负责绘制游戏GUI主界面的背景全景图,这个全景图仅仅是预先拍摄好的图片而已,由客户端主线程控制,足以达到以假乱真的效果。
具体来说,全景图(main menu panorama)绘制逻辑位于net.minecraft.client.gui.GuiMainMenu#drawPanorama内。全景图绘制的核心代码是mc.getTextureManager().bindTexture(TITLE_PANORAMA_PATHS[k]); ,其中TITLE_PANORAMA_PATHS[k]就是全景图的不同部分(六个面),游戏将其绑定纹理,加载到OpenGL的纹理缓冲中,绘制到屏幕上。随着时间的流逝(由 panoramaTimer 控制),全景图还会旋转,给玩家神奇的体验。
0.2 区块是如何加载的?
下面这幅图展示了Minecraft游戏中的区块加载模型(游戏版本:1.12.2 + Forge):

当玩家加入一个服务器、玩家跑图时,会触发区块的加载(当然触发区块加载的原因不止这些)。当世界对象(World)请求一个区块时,这个世界对应的chunkProvider会首先检查这个区块是否已经被生成过。如果已经生成过,则直接从内存区域的区块哈希表缓存id2ChunkMap中查找并返回该区块;否则,如果这个区块从未被生成过,则需要通过区块生成器(chunkGenerator),按照预设的生成算法和规则即时生成新的区块。若缓存未命中,则通过区块IO执行器,以同步方式从本地文件系统中加载区块。经过这一漫长而曲折的过程,就能得到Chunk对象了。
需要注意的是:
- 这张示意图基于Minecraft1.12.2单机游戏模式绘制,并附带forge环境,但并未加载任何mod。
- 图中出现的方法名和类名,使用MCP提供的映射表获得。
chunkProvider在服务端和客户端都有自己的不同实现方式,这里仅仅讨论的是服务端的实现;- 这张图和这段文字,为了突出主要逻辑,略去了一些边界情况(特别是
Null值情况)。
1 | |
这里有一个问题:Minecraft是如何判定一个区块是否已经生成过的呢?其判定逻辑位于isChunkGeneratedAt内:
1 | |
isChunkGeneratedAt 方法通过内存中 (chunksToSave,一个map,包含了即将被写入硬盘的区块,但是不包括正处于写入过程中的区块) 和硬盘上的实际存储情况 (RegionFileCache.chunkExists) 来判断一个区块是否已经生成过。
1.14版本之后,由于Ticket机制的引入,区块的加载过程发生了一定程度的变化。Ticket机制的基本思想是,为需要区块加载的游戏对象分配相应的Ticket,然后根据Ticket的等级进行区块的按需加载。
0.3 Minecraft服务端主线程在做些什么?
和大多数游戏一样,Minecraft的主要游戏逻辑运行在一个个gameTick(简称gt)内。通过翻阅游戏代码,我们可以从net.minecraft.world.WorldServer#tick分析每一个gameTick内执行的任务。下面这张思维导图介绍了服务端世界每一tick所执行的内容:(游戏版本:1.12.2)

注:
- 这张思维导图基于Minecraft1.12.2单机游戏模式绘制,并附带forge环境,但并未加载任何mod。
- 图中出现的方法名和类名,使用MCP提供的映射表获得。
- “冰融化成水”的逻辑是放在冰方块的
randomTick()方法内的,而“水结冰”的逻辑并未放在水流体方块的randomTick()方法内,而是单独提出来处理。原因不明。 - 总世界时间(
totalTime)指的是世界创建以来,所经过的总gameTick数。注意和常用的worldTime作区分。 - 类
WorldServer在1.14版本中的MCP名不同,为ServerWorld。 - 注意区分”方块更新“和”更新方块“这两个概念。前者所执行的才是众所周知的PP更新和NC更新。
- 1.12.2版本中,更新所有实体的逻辑在
net.minecraft.server.MinecraftServer#tick内,而1.16则在ServerWorld#tick中,不同世界的实体更新实现分离。
1 多线程优化之路-总览
2 黎明破晓(1.13)
2.1 版本1.13概述
可以这么说,Minecraft 的多线程优化在 1.13 版本中才真正起步。
Minecraft 1.13 发行于2018年7月18日,无论是在游戏内容还是技术实现上都有着显著变化,以至于Mod社区无法及时适应这些变革,迁移到 1.13 的代价以及门槛都高了很多,这也间接导致大量Mod被迫停留在 1.12.2 版本。
我在这里大致梳理一下 1.13 带来的几个主要的技术性更新:
- ID扁平化。带来的影响算得上是最大的。
- 引入数据包系统。
- 将世界生成过程移动到了一个单独的线程。(后文讨论)
- 引入含水方块。
- 引入PP更新和NC更新(MCP名:
PostPlacement,NeighborChange)。
鉴于本文的主题是多线程优化,所以后续内容将试着分析 Minecraft 1.13 版本是如何将世界生成过程迁移至单独线程的。
2.2 为什么世界生成可以移出主线程?
为什么被Mojang移出主线程的是”世界生成”过程,而不是其他过程(比如实体的更新)?我们先来看看Minecraft的世界生成过程。
2.2.1 世界生成的过程
要分析Minecraft的区块生成过程,我们可以从这三个源码文件进行切入:AbstractChunkGenerator.java、ChunkStatus.java 和 ChunkTask.java。
AbstractChunkGenerator.java文件定义了区块生成器的抽象基类,所有具体的区块生成器(主世界、下界、末地、超平坦、调试等)都继承自这个类。其包含生成地形、结构的核心算法。
为了便于维护,Minecraft将区块生成的过程模块化,划分为多个步骤,每个步骤对应着一个状态,我们把这些状态按照时间顺序(或者说是依赖顺序)串联起来,就得到了一条单向传播的“状态链”。而ChunkStatus.java这个枚举类就是负责管理这些状态的。从这个文件中,我们可以看到,Minecraft的区块生成过程的状态链如下:
1 | |
以下是这些状态的简要介绍:
empty(空白): 初始状态,区块尚未进行任何处理,仅预留空间
base(基础): 生成基础地形,如:生成高度图、放置基岩、放置岩石
carved(雕刻): 在基础地形上进行进一步雕刻,如:生成洞穴和峡谷
liquid_carved(液体雕刻): 在雕刻完成的地形上添加液体
decorated(装饰): 在地形上添加装饰元素,如:树木、植被、矿脉。需要注意:结构生成也在这一步完成。
lighted(装饰): 计算区块中的光照
mobs_spawned(生物生成): 生成生物
finalized(最终化): 完成区块的所有基础处理,准备进行进一步的优化和渲染。
fullchunk(完整区块): 区块达到完整状态,所有数据都已准备就绪,可以被上层游戏逻辑使用
postprocessed(后处理)
这些状态按顺序依次执行,每个状态完成后,区块都会向下一个状态推进,直到区块最终完全生成。有了这条状态链之后,ChunkTask.java文件就可以依照这些状态,创建、执行相应的任务,负责区块生成过程中任务的调度与执行。
2.2.2 世界生成过程的特点
我们从区块生成器中,随机选取一个方法carve来看看它是如何实现的。(不需要读懂,留个印象就行)
1 | |
这个方法的实现比较复杂,涉及到很多的 magical number 以及一些难以理解的算法,但我们可以从中看出Minecraft的世界生成过程的特点:
计算密集性:涉及三维空间内大量的数学计算,这些计算比较耗时,如果在主线程中执行,会占用较多的CPU单核计算资源,有可能显著降低tps。
高内聚性:世界生成过程是高内聚的,基本不依赖于外部状态、也几乎不干预外部状态,与玩家、网络、生物等其他子系统的互动途径有限且可控,对外界实现了解耦。所以这部分工作可以在几乎不影响玩家体验和游戏逻辑的情况下异步、独立完成,也不需要与玩家操作进行对齐、同步。另外,不同的区块生成任务之间也不会相互影响。
确定性:世界生成基于确定的种子和确定的算法进行,因此生成过程是可预测且稳定的。对于同一Minecraft版本、同一种子,无论世界生成算法运行在何时何地,都能保证生成结果的一致性。(当然,在某些场景下,这种稳定性可能被打破,详见这篇Minecraft Wiki)
可分解性:世界生成的过程并不是原子的,可以按照区块分解成多个小任务并行处理。(由于状态链的串行性,如果按照世界生成过程的不同阶段分解成多个小任务,则无法实现并行,只能串行处理)
2.2.3 移出主线程的原因
从上面的分析中,我们发现,世界生成非常适合进行多线程优化,我想这也是为什么Mojang选择在1.13版本中进行这项改进的原因。
促使mojang将世界生成移出主线程的原因无非就两点:对性能提升大、实现起来安全且简单。
首先就是性能提升。考虑到世界生成的计算密集性,将其移动到单独的线程是一笔非常划算的投资。
其次,实现起来安全且简单。在上文中,已经提到过世界生成过程具备三大特征:稳定性、高内聚性、可分解性。这三大特征使得世界生成过程的多线程实现变得比较简单且安全。
2.3 是怎样实现的?
2.3.1 结构性基础:Scheduler
net.minecraft.util.Scheduler#Scheduler是世界生成的异步化基础,我们在调试工具中看到的Scheduler线程和Worker线程就是由它创建的。为了更好地理解Scheduler是如何工作的,我们看看其构造函数代码:
1 | |
concurrency参数表示并发级别,在1.13的代码中,传入Scheduler的concurrency值始终为2,所以上面代码中的有些分支永远不会cover到。
构造函数内部创建了两个重要的对象:
schedulerPool: 一个单线程executor (Executors.newSingleThreadExecutor()),用于封装和预处理任务。workerPool: 一个ForkJoinPool线程池,每个ForkJoinWorkerThread都有一个唯一名称name-Worker-X(X是递增的工作线程 ID)。世界生成就是在workerPool中执行的。
ForkJoinPool 是 Java 1.7 引入的并行计算框架,提供了一种简单但是高效的分治计算模型。在1.13版本中,workerPool 的大小为 concurrency - 1,因为传入的 concurrency 为 2,所以 workerPool 的大小恒定为 1。下面是 ForkJoinPool 的原理图:
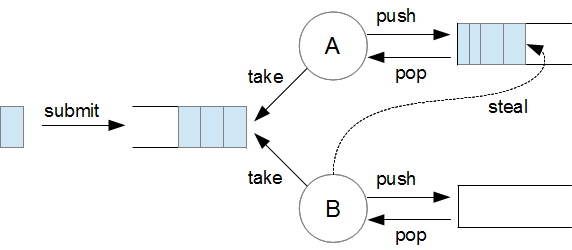
Scheduler 的 schedule 方法是用来提交任务的,是 Scheduler 的核心方法,其实现如下:
1 | |
2.3.2 世界生成的调度者:ProtoChunkScheduler
前面提到的 Scheduler 是一个抽象类,而 ProtoChunkScheduler 则继承自 Scheduler。ProtoChunkScheduler 持有区块生成器 chunkGenerator ,通过它来从头开始,生成 ProtoChunk。
ProtoChunkScheduler负责将区块请求按照一定顺序入队,按照前面提到的状态链,将区块生成过程分解成多个小任务,随后将这些小任务封装成future,提交给 workerPool 执行。
这里的ProtoChunk指的是 Minecraft 中接口IChunk的两种实现之一,即 ChunkPrimer(也可以称为 PROTOCHUNK),与之相对的是 Chunk(或 LEVELCHUNK)。ChunkPrimer 主要用于世界生成过程,而 Chunk 则用于游戏运行时的逻辑处理。当区块生成完毕后,ChunkPrimer随即转换为Chunk。
2.3.3 任务提交流程
在本文的“前置知识”部分,我们提到过 ChunkProviderServer 是一个 IChunkProvider 的实现,负责提供区块给上层游戏逻辑。
具体一点来说,ChunkProviderServer 的 provideChunk 方法是上层逻辑请求区块的入口,当缓存中没有找到指定位置的区块,并且该区块也没有落盘存储过时,它会通过taskManager来调用 ProtoChunkScheduler 的 schedule 方法,把请求以batch形式入队,随后处理。
1 | |
至此,我们可以归纳出调用链条:
1 | |
关于具体实现的讲解,就到此为止了。
2.4 思考:为什么不再多开几个线程?
从某种程度上来说,1.13版本的世界生成优化,依然存在局限性。
如果使用VisualVM查看当前游戏进程中的活跃线程,我们只能看到一个调度线程和0~1个世界生成worker线程,所以说worker线程的数量是被严格限制在1以内的,无法根据需要动态扩容。

这就引起了笔者的好奇,我打算通过修改游戏的源代码来增加世界生成的 worker 线程数量(大于等于2),以此来测试这是否会提高游戏性能,或是反而导致游戏崩溃。
为了实现这个想法,笔者编写了一个Mixin Mod,来修改游戏代码中 Scheduler 的构造函数,以此来控制 worker 线程的数量。但是实现过程遇到了诸多问题,这里按照时间顺序记录一下。
2.4.1 问题1:找不到package
由于Forge在Minecraft版本1.16之后才内置了Mixin支持,所以在1.13中需要手动安装 org.spongepowered.mixin 这个库以实现Mixin代码的动态注入功能。在 build.gradle 文件中配置好 annotationProcessor 后,不出意外的话,应该就可以直接在 Mixin 类中定义方法,并使用相应的注解来指定需要注入的位置。
然而在编译过程中还是出现了错误,提示说找不到 org.spongepowered 包。为了解决这个问题,笔者手动下载了对应的 JAR 包,并将其放置到项目的 build/libs 目录下。接着在 build.gradle 文件中添加对该 JAR 包的引用,这样就能顺利通过编译。
2.4.2 问题2:mixin host 服务不可用
按照上述过程引入了mixin插件后,编译通过了,但是客户端程序启动时还是报错:
1 | |
Github上有人提到过这个问题,issue链接:https://github.com/SpongePowered/Mixin/issues/286
归根结底,还是因为1.13版本过于古老了。SpongePowered Mixin项目维护者Mumfrey指出LaunchWrapper不支持1.13版本,如果执意要在1.13版本上使用Mixin,需要自行解决兼容性问题,而且强烈建议不要这么做。
所以,笔者只好放弃了在1.13版本上使用Mixin的想法,转而选择另一种解决方案,即MCP-Reborn。
2.4.3 问题3:MCP-Reborn部分资源文件已经失效
借助MCP-Reborn这个项目,我可以直接修改游戏代码,然后编译运行。但是在gradle.build过程中,构建系统下载的一些资源文件已经失效了,导致构建失败。构建系统输出的错误信息如下:
1 | |
看样子是资源服务器挂了,可能作者已经不再维护1.13版本了。目前我已经提了issue给作者,希望能尽快修复。
所以修改游戏代码的想法也就暂且搁置,交给时间吧。
3 持续深入(1.14)
3.1 版本1.14概述
1.14版本的Minecraft对光照系统进行了重构,将光照计算从主线程移除,在专用线程中处理光照。这是继1.13版本引入的异步世界生成之后,Minecraft的又一次多线程优化尝试。
与世界生成相比,光照计算的异步化要困难一些,它和其他系统的耦合程度更高,在线程安全上也更加复杂。因此mojang实际上做了更多的事情,如:将光照数据的存储处从区块移动到单独的结构。关于具体的技术细节,且听后续分解。
注意:
如未经特殊说明,下文中提到的1.14版本的游戏代码全部默认使用官方mapping,因此下文中提到的类、方法等名称均不是MCP名。换用官方mapping,一是因为MCP的命名不完善,有大量的方法名和字段名都没有被映射,造成阅读理解上的困难;二是因为MCP毕竟是逆向而来的工程,在命名上难免会有一些不准确的地方,可能无法准确反映开发者的意图。
3.2 光照计算的简要介绍
3.2.1 什么是光照计算?
在Minecraft技术圈中,大家经常提及的“光照计算”是什么?
一般我们认为“光照计算”是指游戏确定每个方块处亮度值的过程。这个亮度值是0(最暗)~15(最亮)之间的正整数,对于视觉效果、怪物生成、植物生长等游戏逻辑都有着决定性的作用。进行光照计算时,以下因素是需要我们重点考虑的:
- 方块光照:由光源方块(如火把、萤石)产生的光,会传播到相邻的方块,光照强度随着中心距离增加而递减。
- 天空光照:在露天环境中,天空提供的光照等级固定为15。天空光照不会随时间变化而变化(就算是晚上)。
- 光介质:全透明或半透明方块不会完全阻挡光线通过,但是光线会被吸收,导致光照传播距离变短。
由于本文的主题是“多线程优化”,因此我们暂且不讨论光照计算的具体算法,只谈谈它的异步化。
3.2.2 游戏会在什么时候执行光照计算?
这里以1.14为例,游戏执行光照计算的时机有很多,但在大部分时候,只有两种情况会触发光照计算:
世界生成。前文在“世界生成”一节中提到过,光照计算是世界生成的一个重要步骤,这样生成的光照就是我们刚刚踏上一片新的区块时看到的光照。
方块状态改变。当实体放置/破坏方块、TNT摧毁方块、岩浆流动等事件发生时,游戏会自动触发光照检查,重新计算由于方块状态改变而影响到的周围亮度。
1 | |
笔者做了一个小实验:删除掉上面的这一行代码,然后重新编译并启动游戏,观察光照变化。结果显而易见,当我挖掉地面上的一层土块后,土块所在地的光照等级没有得到更新(依然为0),导致被挖掉的地方看起来非常昏暗:

3.3 新旧版光照系统的简要比较
3.3.1 1.14之前的旧版光照系统是怎样的?
这里选取1.13版本的旧版光照系统作为例子,来看看它的实现。
光照系统的代码在1.13版本中比较分散,一部分代码集中在SkyLightEngine和BlockLightEngine两个类中,另一部分则散落在Chunk和World类中。下面这张图展示了区块生成过程中,光照计算的调用逻辑。

当区块生成执行到光照计算阶段时,任务管理器会创建一个光照计算任务,这个任务接着会创建两个光照引擎SkyLightEngine和BlockLightEngine,一个用于计算方块光照,另一个用于计算天空光照。光照引擎的核心方法是calculateLight,它会执行一定程度的遍历,逐个计算方块亮度值。计算过程中,会调用Chunk类中的一些方法,主要目的是为了读写区块对应的NibbleArray,这个NibbleArray存储了每个section中的方块的亮度值。但这也会影响到线程安全。
除了上述光照代码外,还有另一部分光照逻辑散落在World类中,如World#checkLight方法负责执行光照检查,在每一游戏刻运行过程中,光照检查都是必不可少的。这个方法比较复杂,这里不做探究。这个方法运行在主线程中。
值得注意的是,SkyLightEngine和BlockLightEngine仅仅在区块生成时使用,在其他时候并不会被调用。
综上,我们可以按照异步程度,把1.14之前的光照系统分为割裂的三个部分:一部分是同步计算,会阻塞主线程;另一部分是异步计算,在worker线程中执行;最后一部分既有可能同步也有可能异步,由调用者所处的线程决定。同步计算的部分包括World#checkLight方法;异步计算的部分包括SkyLightEngine和BlockLightEngine,它们属于世界生成的若干个环节之一,与世界生成的其他过程平等,一起共享相同的worker线程资源;Chunk类中一些读写NibbleArray的操作,则既有可能同步也有可能异步,由调用者所处的线程决定。
3.3.2 新版光照系统做了哪些结构性改进?
1.14版本的光照系统与1.13版本有很大不同,它把光照逻辑整合在一起,使用ThreadedLevelLightEngine来实现异步计算。
3.4 具体实现的详细讲解
3.4.1 光照计算的异步基础:ProcessorMailbox
Minecraft在1.14版本中为了实现异步光照计算(顺便兼顾1.13版本的异步区块生成),专门开辟了net.minecraft.util.thread包,其中定义了StrictQueue接口和ProcessorMailbox等类。这些类提供了一种基于容器的消息传递机制,用于在不同线程之间通信,来达到传递计算任务的目的。其本质上就是一个由mojang手搓的消息队列 + 二次封装的forkJoin线程池。
值得注意的是,在异步光照计算基于ProcessorMailbox实现的同时,mojang也将1.13版本的异步区块生成迁移到了ProcessorMailbox,使得光照计算和区块生成均基于一致的底层机制。
什么是ProcessorMailbox?我们先从一些它的依赖项入手,下面这张UML图展示了ProcessorMailbox的基本依赖结构:

StrictQueue只是一个接口,定义了一个严格队列的行为。具有泛参 T F,分别代表入队、出队元素类型。StrictQueue接口窄化了对Java集合框架的顶级接口Queue的方法的访问权限,仅仅提供了基本的队列操作 pop, push 和isEmpty方法。StrictQueue 包含了两个内部类:FixedPriorityQueue 以及 QueueStrictQueue,这些类实现了 StrictQueue 接口。
顾名思义,StrictQueue的实现是严格的,普通队列允许违反顺序(如使用 remove() 方法删除队列中间的元素),而 StrictQueue 不提供这样的操作。
这里以其具体实现FixedPriorityQueue为例:
1 | |
FixedPriorityQueue内部的queueList维护着多个优先级队列,每个优先级队列按照其自身的优先级进行排序。当元素入队时,它会根据自身的优先级,放入到对应的优先级队列中;当队列出队时,会按照优先级顺序,依次从各个优先级队列中出队一个元素。需要强调,这个FixedPriorityQueue并不是传统的基于堆(or 二叉树)的数据结构。
接下来介绍一下ProcessorMailbox:
ProcessorHandle也是一个接口,用于处理消息传递,其定义了一个消息处理器的基本行为——发送消息 (tell)、询问 (ask) 、关闭 (close) 。
ProcessorMailbox实现了ProcessorHandle接口,其内部使用一个StrictQueue作为其内部队列来存储待处理的消息,并通过依赖于一个外部Executor来实现多线程处理。这里并没有规定内部队列和线程池的具体实现,而应当根据实际需要选择合适的,比如:对于1.14的区块生成和光照计算任务,ConcurrentLinkedQueue会作为ProcessorMailbox的内部队列来使用,确保了线程安全。其本质上就是一个消息队列+Executor 的二次封装。
另外,ProcessorMailbox维护了一个有限状态机(原子整数)来跟踪自身状态(是否已经关闭、是否已被调度),根据状态决定何时将自身注册为可执行任务,便于流程控制。其状态图如下:

在MCP的映射表中,ProcessorMailbox的名称为DelegatedTaskExecutor,从名字可以看出,它是用来委托任务的执行器。这两个名称共同表明了其异步桥梁的作用。
3.4.2 ProcessorMailbox的应用例子
上面讲了ProcessorMailbox的基本概念和实现,也许比较抽象,不容易理解,所以下面我们来看看它的具体应用。
下面这段代码展示了ProcessorMailbox的创建过程:
1 | |
worldgen和light任务共用Util.backgroundExecutor()返回的执行器,这个执行器依然采用了ForkJoinPool作为基础线程池,其生成过程如下:
1 | |
这里有个小问题:为什么这个线程池采用FIFO调度模式,而不是默认的LIFO模式?这其实是为了配合FixedPriorityQueue的设计,后者会按照优先级顺序线程池提交任务,因此采用FIFO模式可以保证任务的执行顺序与入队顺序一致,确保优先级高的任务先执行。
创建出来的一系列线程名是Server-Worker-n,这与我们在visualvm中看到的线程名一致:

processorMailbox.tell()的使用示例如下:
1 | |
tell()在这里起到了发送消息的作用,将一个Runnable对象(这里是lambda表达式)发送到ProcessorMailbox的内部队列中等待执行,不等待返回结果。ask()也起类似的作用,但是它会返回一个CompletableFuture,用于异步接收消息处理结果。所以,顾名思义,ask()相当于tell()的异步版本,在发出询问之后还要等待对方应答。
3.4.3 光照计算的集中实现——ThreadedLevelLightEngine
1.14把光照计算逻辑集中在了ThreadedLevelLightEngine中,无论是世界生成还是光照检查,都由ThreadedLevelLightEngine来统一管理。

从上面的UML图可以看出,几乎所有方法都是基于addTask方法来添加任务的,而addTask方法又会调用ProcessorMailbox的tell方法来发送任务到ProcessorMailbox的内部队列中,进而由专用线程处理。这就和前面的内容对应上了。
4 陷入停滞,缝缝补补(1.16,1.18)
从1.15及以后,Minecraft的每次大版本更新,基本上就没有太多关于多线程优化的改动,而是更多的游戏内容更新。
1.16的优化主要集中在区块文件写入方面,1.18的优化则集中在区块构建方面。
以下内容援引自Minecraft Wiki,仅供参考。
4.1 版本1.16
区块文件现在以同步模式写入,以防崩溃后数据丢失并损坏。
专用服务器可以通过更改server.properties中的sync-chunk-writes来禁用它。
4.2 版本1.18
4.2.1 区块构建器
1.18版本中新增的“区块构建器”选项,提供了不同的策略来控制区块的编译方式,以平衡性能和视觉效果:
在视频设置中加入了“区块构建器”选项,用于确定在单个帧期间同步更新区块的哪些部分。
- “全阻塞”是最保守的策略,即先前版本中的策略。附近的区块总会被立刻编译。这可能影响放置或破坏方块时的游戏性能。
- “半阻塞”和“线程化”是新策略,会显著减少放置或破坏方块(尤其是光源)时的卡顿,但有较低的概率可能会导致在世界更新过程中出现视觉上的明显延迟。
- 半阻塞:区块内部的某些行为会导致区块立刻重新编译。这包括放置或破坏方块。
- 线程化:附近的区块会在并行的线程中编译。这可能导致破坏方块时短暂出现图像空洞。
笔者注:这个设置项的默认值为“线程化”。
Minecraft中,“编译区块”(或叫做“构建区块”)是指游戏对区块进行渲染准备的过程。如果某些游戏逻辑对区块作出了修改(如末影人放置方块),这个修改所在的区块就需要更新其渲染信息,提交给GPU进行渲染,不然玩家就观测不到这些变化了。这个过程运行在客户端,并且可以并行化。
区块编译结束后,渲染数据会被上传到GPU,具体上传过程取决于玩家是否启用Vertex Buffer(顶点缓冲)。
4.2.2 线程池大小调优
- 线程池的大小为:可用CPU线程数 - 1,现在默认的上限是255,而不是以前的7。而此上限可以由Java系统属性`max.bg.threads`所决定。
5 来自第三方社区的努力
5.1 MCMT(1.15)
下面来聊聊异步区块加载。(当然MCMT的优化范围可不止区块加载)
5.1.1 Forge的asyncChunkLoading设置项
其实Forge自身也给出了允许区块异步加载的asyncChunkLoading设置项:
# Load chunks asynchronously for players, reducing load on the server thread.
# Can be disabled to help troubleshoot chunk loading issues.
B:asyncChunkLoading=true
Forge通过修改游戏源码,实现了:如果asyncChunkLoading设置为 true ,server会异步加载区块,不阻塞主服务器线程。asyncChunkLoading控制着游戏代码中minecraftforge.common.ForgeChunkManager.asyncChunkLoading这一标志位,当其开启后,游戏会尝试使用queueChunkLoad这一异步方法去访问本地文件系统以加载区块,而不是调用syncChunkLoad去占用当前线程(多数情况下是主线程)。queueChunkLoad是基于线程池实现的,性能也还不错,对于玩家跑图时FPS的提升比较可观。
1 | |
但这种优化也存在局限性,尚存提升空间。首先,区块provider仅仅在需要从本地文件系统读取区块时,才会进行多线程优化,其他情况下,区块的获取依然会阻塞当前线程;其次,在从本地文件系统读取区块之前,provideChunk()方法访问的id2ChunkMap缓存、和判断区块是否已经生成过的方法isChunkGeneratedAt()都不是线程安全的。因此,经过Forge优化的 getChunk() 依然并不直接支持多线程环境下的并发调用,其并发安全性不能满足高并发需求。
5.1.2 MCMT的横空出世
有幸的是,一个名为Minecraft Multi-Threading(MCMT)的优化模组,将这条性能优化之路,继续走得更深更远。
MCMT是一个Minecraft模组,可使 Minecraft 的一些内容使用多线程处理,如世界(World)、维度(Dimension)、实体(Entity)、方块实体(TileEntity)、随机刻、区块等。
MCMT通过修改服务端进程(独立服务端&单人游戏的内置服务端),dispatch所有的世界,方块实体,随机刻(environment ticks)等,到一个线程池里,使游戏能并行处理内容。安装后单人模式相比原版的tps平均提高了50%甚至更高,在多人游戏中可能会更高。
–摘自MC百科

原版的ServerChunkProvider在设计时并未充分考虑多线程环境下的线程安全问题。例如getChunk方法在多线程环境中可能会导致竞态条件。
为了克服这个挑战,MCMT引入了一个新的类ParaServerChunkProvider,直接覆盖了原版的ServerChunkProvider,引入了若干改进。
ParaServerChunkProvider转而采用了线程安全容器ConcurrentHashMap(chunkCache),用于缓存已经加载过的区块。当请求一个区块时,如果该区块已经在缓存中,则直接返回。为了跟踪chunkCache的访问情况,使用了一个线程安全的原子整数access,每次访问或更新chunkCache时,access值都会递增,用以记录最后一次访问的时间。
为了确保缓存不会无限制增长,ParaServerChunkProvider建立了一个单独的清理线程,该线程周期性地追踪并移除不再需要的缓存项。缓存项的移除遵循近似LRU原则。通过计算chunkCache的填充程度(实际大小与最大容量的比例),可以确定一个“截止访问时间”(cutoff)。所有最后访问时间小于cutoff的缓存项将被清理掉。
其次,就是加锁。ParaServerChunkProvider利用ChunkLock类来实现细粒度锁机制。ChunkLock服务于ChunkLockPool,后者管理着一组锁,每个锁对应一个特定的区块区域。当请求加载一个区块时,会获取该区块所在区域的锁,从而确保对同一区块的加载操作是序列化的,而对不同区块的加载则是并行化的。loadingChunkLock实例用于控制对特定区块(以chunkPos为中心、边长为2*radius+1的正方形区域内所有区块)的加载操作。

这里补充说明一个由于并行加载的区块过多而导致的内存占用问题:
从1.15.2开始,每个区块加载前,会创建一个回调函数(Lambda表达式),用来等待区块加载完毕后从NBT数据中加载实体信息。而这个Lambda表达式持有闭包作用域内的NBT Compound对象(NBT Compound是非常大的对象)。在同一段时间内,如果大量区块正在加载,且加载还没达到FULL状态时,这些大对象由于被这个回调函数所引用,无法GC掉,会引起明显的内存占用。
一个来自PaperMC的非官方patch对此做出了修复:为了避免持有不必要的NBT数据,引入了一个名为SafeNBTCopy的新类,这个类只复制NBT数据中的TileEntities和Entities两个部分,不再保留整个NBT Compound的引用,确保只保留加载实体所需的最小数据量。
Sponge的开发文档也指出,缓存某些类的实例,以及任何可能存储这些引用的容器,都有可能导致内存泄漏(OutOfMemoryError)、延迟或程序行为不一致,应尽力避免,可以通过诸如使用对应快照、保存对应的 UUID 或按需请求实时实例来避免。链接在这里
5.2 Folia(2020.8)
5.2.1 Folia简介

Folia是PaperMC组织下的一个项目,旨在为Minecraft服务器提供真正的多线程和区域化的区块更新机制。这个项目由著名的Minecraft优化专家Spottedleaf发起,开发始于2020年8月。Folia通过一系列的前置补丁,如Starlight、玩家区块地图(player chunkmap)以及区块重写(chunk rewrite),解决了长期以来限制服务器扩展的一些问题。
在Folia中,邻近的已加载区块被组合成independent region(独立区域),每个region都有自己的更新循环,以常规的Minecraft更新速率(20 TPS)运行。不同region的更新循环在一个可配置的线程池中并行执行。
Folia已经成功在一些大型服务器上进行了测试,(如2b2t和DonutSMP)。2b2t升级到1.19版本后,由于采用了Folia而运行得非常流畅;DonutSMP则部署了多个Folia实例来支持其庞大的SMP网络,每天能承载数千名玩家在线,处理超过46万个实体。
想要更深入地了解Folia,可以阅读它的官方仓库。
这是一篇详细介绍Folia的文章:https://www.paper-chan.moe/folia/,但是没有涉及太多的技术细节。

5.2.2 关键概念——独立区域
在Folia中,邻近的已加载区块被组合成所谓的independent region(独立区域)。这一机制是Folia实现真正多线程的关键部分。独立区域是指一组相邻的已加载区块位置以及与之相关的唯一数据对象。我们可以得出其重要性质:不会同时有两个活跃区域持有同一个区块。
如果两个独立区域的边界接近,则它们可能会合并成为一个更大的区域。反之,如果一个大区域内区块之间的距离增加,那么该区域可能会分裂成更小的独立区域。
每个独立区域有自己的更新循环(tick loop),按照Minecraft的标准更新速率(20 TPS)进行更新,并且每个区域独立维护自己的下一次tick的时间点。这些更新循环是在一个多线程池中并行执行的,因此不存在一个统一的“主线程”来处理所有区块的更新。每个独立区域不是拥有一个独立的线程,而是共享一个多线程池中的线程资源。
对于玩家空间分布较广的服务器,Folia就可以创建许多分散的独立区域,并且并发更新这些区域,这比原版中一次更新一个世界的顺序方法要高效多了。在CPU核心数充足的情况下(Folia在至少拥有16个物理核心的CPU上运行效果最佳),这种设计可以带来显著的性能提升。


5.2.3 实现细节

为了便于表述,本章节以下出现的所有“区域”一词,均指代“独立区域”。
独立区域的创建、合并和分离是由Regioniser根据基础的区域化逻辑自动处理的。我们可以把活动的区域想象成气泡,当两个气泡靠近时,它们会合并成一个更大的气泡。每个世界都拥有自己的Regioniser,其主要职责是创建、维护和销毁区域。维护过程主要有三个:合并附近的区域、标记哪些区域可以进行tick处理、将某些区域分裂成更小的独立区域。
Regioniser提供的保证:
- 第一不变量:不会同时有两个活跃区域持有同一个区块。
- 第二不变量:对于区域内的每一个区块
x,其周围一定范围内的区块都属于同一个区域,以确保一个区域在执行tick时不会受到其他区域的影响。 - 第三不变量:正在执行tick的区域不能在这个过程中扩展其所拥有的区块范围。
- 第四不变量:区域只能处于四种状态之一:“暂存”、“就绪”、“tick中”或者“死亡”(”transient”, “ready”, “ticking”, or “dead”)。
在具体的世界分块过程中,Regioniser会将世界分割成多个区域,每个区域为一个NxN的区块网格,其中N是2的幂。例如,当N=16时,区域区块坐标(0,0)包含了所有x在[0,15]和z在[0,15]范围内的区块。
对于一个非tick中的非死亡区域x,可以向tick中的区域y发起稍后合并请求。该操作记录在x和y的待合并集合中。当y完成tick处理后,会执行所有待合并的操作。
任何正在进行tick处理的区域必须最初拥有一个小的外围缓冲区,这些额外的区块保证了在tick处理过程中,该区域不会与其他区域产生直接的相邻关系,以满足第二不变量,从而避免竞态条件。而且区域不得在有相邻的直接邻居区域的情况下开始tick处理,可能也会影响彼此的数据一致性。
6 结语
写到这里,本文的主要内容已经介绍完毕。如果你想要对 Minecraft 的多线程优化有更深入的理解,或是想探索更底层的东西,那么可以继续阅读文末的延伸阅读部分,相信你会有所收获。
附录:延伸阅读
多线程优化是一门很繁琐的系统性工程,对于像 Minecraft 这样复杂且历史包袱厚重的游戏来说,更是如此。我在这里浅尝辄止,把探索的机会更多地留给读者。我在接下来的附录中列出了一些大佬的文章和项目,尽可能多地为读者提供一些额外的研究方向和资源,以供进一步深入。
延伸阅读1:一种基于区域锁的并行化模型
由 海螺 提出的一种比较激进的Minecraft服务端并行化方案,引入了”区域”这一概念,将游戏中的各种逻辑运算抽象为事务,并利用基于”区域”的细粒度锁来保证并发安全性,优化思路在某些方面类似于事务型数据库。很可能需要重构整个游戏才能实现。
他的这篇文章比较硬核,信息量也很大,阅读前请做好相关知识储备。
本文将会以 Minecraft 为例介绍 3D 沙盒游戏服务器的运行模型、该单线程模型的限制,提出一种可行的、基于区域锁的并行化模型,分析其可行性,并给出对应的实现细节、调度优化方法等。
博文链接:一种沙盒游戏服务器并行化设想
延伸阅读2:线程数量太多导致的性能下降
有时候,线程数量太多反而不是一件好事。
“为什么自从1.14版本开始Minecraft启动时会消耗大量CPU?” 这个问题的答案是:Minecraft在启动期间创建了太多的线程(没有考虑CPU物理核心的数量限制)来重写DataFixer类型和加载资源,而且这个过程会让GC非常活跃,进一步加剧CPU负载。如果此时的密集型任务线程数量多于CPU物理核心数量,那么线程之间就会产生频繁的竞争,在宏观上导致游戏加载得更慢,甚至你的电脑可能开始卡顿,因为留给操作系统相关任务和其他应用程序的CPU时间减少了。
由 saharNooby 开发的Minecraft Thread Pool Agent模组用于优化Minecraft的启动速度,而且还能解决加载完成后主菜单持续高CPU占用的问题。通过调整Minecraft内部使用的线程池大小来实现优化效果,适用于客户端和服务端,可以支持到原版、Spigot、Forge、Fabric。
该模组的MCMOD百科:https://www.mcmod.cn/class/3423.html
Github(介绍了技术细节):https://github.com/saharNooby/minecraft-thread-pool-agent