强悍性能 LevelDB 养成记

强悍性能 LevelDB 养成记
gy前言:LevelDB 的小身材和高性能
LevelDB 是 Google 开源的一套单机 KV 存储引擎,定位非常明确:不做 SQL,不做复杂事务,甚至连多进程共享都不是它要解决的问题。它把工程目标收得很窄,只专注于把写入吞吐、读延迟、磁盘占用和崩溃恢复这几个核心指标做成一套自洽的系统
从代码体量看,LevelDB 确实轻量,源码加上文档、benchmark 也就几百 KB,移植到资源受限的设备并不离谱。
但他性能逆天,原因不神秘:这套实现基本是在围绕 LSM-tree 的放大因子做控制,同时在热路径上用了一堆偏底层的手段把不确定性压下去,比如顺序 I/O、缓存粒度、引用计数 pin 住对象、后台异步 compaction 等 后面会细讲
LevelDB 不是关系型数据库,也不支持 SQL。对外主要接口就是 Get、Put、Delete,以及 iterator 范围扫描
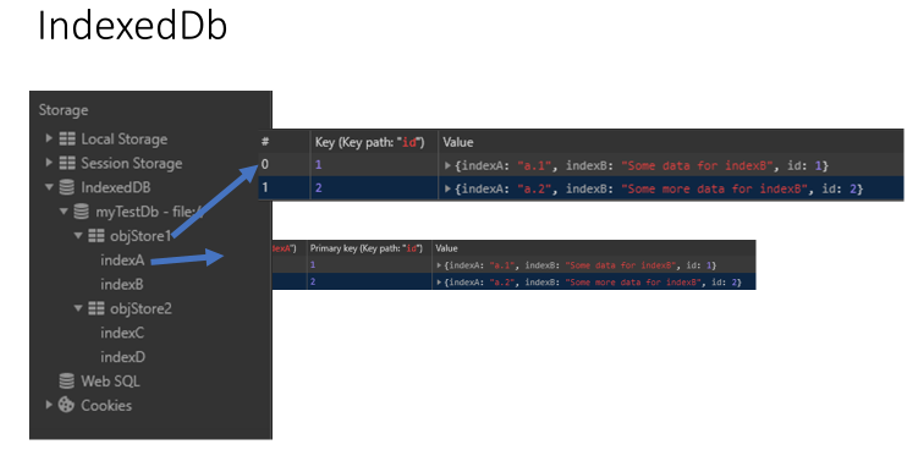
你经常能在这些地方看到它:Chrome 的 IndexedDB/Local Storage/Session Storage 等存储组件,底层都有 LevelDB 参与;Minecraft 基岩版的世界存档也用 LevelDB 生态的分支实现
Chrome:
MC 基岩版由于 leveldb 故障而形成的地图加载异常:
总览:从接口到磁盘,LevelDB 这条链路怎么串起来
一言以蔽之:前台由 DBImpl 扛住读写请求,后台用 compaction 慢慢消费 LSM;版本系统 Version/VersionSet 负责把一堆 SST 文件组织成一个可查询、可迭代、可回收的整体视图
写侧最靠近用户的是 WriteBatch。这玩意不是单纯的 API 壳子,它的二进制布局就是为 WAL 落盘和 crash replay 设计的,序列化后直接进 log::Writer 做顺序追加。数据进入内存会先落到 MemTable,这块是跳表 SkipList + Arena 统一分配的组合,写进去的其实是 internal key:user_key + sequence_number + value_type
读侧看上去就是查一个 key,但实现上更像是 iterator pipeline:先查 mem_ / imm_,再由当前 Version 提供的文件组织去查 SST。SST 这边靠 TableCache 管表对象生命周期,靠 block cache 缓存 data/index block,再用 filter block 布隆过滤器做一次 membership test,把大量“不可能命中”的 IO 直接挡在外面(后面我会详细讲一下 leveldb 对 bloom filter 的实现,我挺感兴趣的)
最重要的后台机制是 compaction。它是 LSM-tree 背后的安卓力工,归并、去重、清理 tombstone、控制每一层的 size limit,保证读放大不会失控,同时把写放大的波动压到后台去消化

LSM-tree 之 InternalKey、snapshot、删除不是删除
LSM-tree 真正工程化之后,最容易被忽略的其实是 key 的语义。
用户看到的是 user key,但在 LevelDB 内部,数据用 InternalKey 编码,内部排序由 InternalKeyComparator 定义。InternalKey 由三部分拼起来:user key、全局单调递增的 SequenceNumber、以及 ValueType。这三个字段让 LevelDB 在不做复杂事务的情况下,依然有了 MVCC 语义:同一个 user key 可以同时存在多个版本,读路径通过 snapshot sequence 选择“可见版本”
这也解释了一个现象:删除不是立刻擦除,而是写入一个 deletion marker,也就是 tombstone。真正的数据回收发生在 compaction 时机,并且只有当 Compaction::IsBaseLevelForKey() 这类条件成立,才会把过期版本或删除标记 drop 掉。这个策略让写路径保持 append-only,同时把空间回收的复杂度集中并转嫁到了后台
写入链路之 WriteBatch、WAL、MemTable,为什么能把延迟压的很平
写入的入口最终都会落到 DBImpl::Write(),LevelDB 在这里做的事情依旧非常的数据库:先写 WAL,在写 memtable
并发模型也很清晰:写线程通过 writer queue 合并成一个 batch group,减少 syscall,同时避免大量小写把 log 记录切得太碎。BuildBatchGroup() 会把多个 Writer 的 batch 合并到一个 WriteBatch,并用 WriteBatchInternal::SetSequence() 分配连续 sequence
这段代码很能代表它的关键顺序:
1 | |
这就是典型的 write-ahead logging。只要 WAL record 可靠落盘,进程崩溃后就能 replay 回 memtable,再走 flush 生成 SST。这里的 options.sync 决定了 durability 边界:不开 sync,你得到的是更高吞吐和更低延迟,但 crash 时可能丢最后一截没有 fsync 的尾巴
写路径还有一个容易被忽视的细节:MakeRoomForWrite() 对 level-0 文件数量做了节流,kL0_SlowdownWritesTrigger 会让写入线程做微小 sleep,尽量把延迟方差抹平;kL0_StopWritesTrigger 直接 hard stop,逼 compaction 跑起来。我猜这是为了前台稳定性优先,不知道各位怎么看
重难点之 MemTable:SkipList + Arena,读路径为什么能几乎不掺锁(吗?)
Memtable
MemTable 的底层结构是 SkipList,配合 Arena 统一分配。跳表的价值不只是 O(log n) 的期望复杂度,更多是它的并发可见性更容易做对。
LevelDB 的跳表实现会在指针发布上用 acquire/release 语义,让读线程看到的是“完全初始化”的节点。它不是完全 lock-free,但读路径不需要在数据结构层面做复杂的旋转和重平衡,也不需要为 delete 做回收,写入只增不减,删除由 tombstone 表示,这让内存管理变得非常线性
MemTable 在内存里,所以可靠性靠 WAL 兜底。LevelDB 的顺序就是先向日志写 record,再向 memtable 插入
跳表的并发安全核心在于 Node 结构体的指针访问方法:
1 | |
下面几个操作实现了内存序配对:
- SetNext() 保证节点初始化完成后才”发布”指针
- Next() 保证读到指针后能看到节点的完整状态
- NoBarrier_* 用得少,无同步保证

imm_memtable
当 memtable 到阈值会冻结成 imm_,后台线程把 imm_ flush 成 SST。可在 DBImpl::MakeRoomForWrite() 看到切换:旧的 mem_ 变成 imm_,然后创建新的 log file 和新的 mem_,并通过 MaybeScheduleCompaction() 把后台任务丢给 Env
SSTable 剖析:如何写出对 CPU cache 友好的代码?
SSTable 是 LevelDB 真正的磁盘数据结构。并不是⏰大学教材最爱的每条记录一个磁盘位置那种设计,而最小 IO 粒度是 block。data block 顺序排布,配上 index block 和 metaindex block,文件尾部有固定 footer 和 magic number。
整块 sstable 长这样:

sstable 的构建入口是 TableBuilder,块内编码也很讲究:BlockBuilder 走 前缀压缩 + restart points。为了省空间,相邻 key 的公共前缀会被压缩掉,因此需要每隔 block_restart_interval 插入一个 restart point 来完整存储 key(也就是 shared_bytes == 0),读时先二分定位 restart,再在局部线性 scan,兼顾压缩率和 seek 成本
每个 data block 长这样:

这里的 restart points 不只是为了省空间,它其实在影响一次随机读的 CPU cache footprint。因为 block 的查找路径是先在 restart array 上二分(不开启布隆过滤器是这样的),再在 restart block 里线性推进解析 entry。如果 restart interval 太大,线性扫描会变长,CPU 前端的分支预测压力和 L1/L2 miss 都会非常难看,没法有效利用执行资源;如果 restart interval 太小,restart array 变大,block 的尾部元数据占比上升,同样会挤压有效负载。合理的 interval 应该让一次查找的工作集限制在几个 cache line 内,比如 16:
1 | |
BlockBuilder::Add() 里 restart point 的触发很直白:
1 | |
另外一个很sys味的点是 index key shortening。TableBuilder 并不会在每个 data block flush 的瞬间就把 index entry 写进去,而是把 handle 暂存起来,等看到下一个 data block 的第一条 key 之后,才把上一块的 index key 短化,然后再落到 index block。这么做的目标很明确:让 index block 的 key 更短、熵更低,block cache 命中时需要解析和比较的字节更少
短化逻辑靠 comparator 提供的两个接口 FindShortestSeparator() 和 FindShortSuccessor()。核心代码在 TableBuilder::Add() 和 TableBuilder::Finish():
1 | |
把它和 two-level iterator 放一起看就更直观了:随机读会先命中 index block,再定位到 data block,再做 block 内 restart-array + 局部 scan。index key 越短、restart interval 越合理,越容易把一次读请求的工作集限制在几个 cache line 里,读路径的尾延迟就越稳
接下来我们的 MVP 布隆过滤器要出场了
读路径最核心的三件事是:TableCache、two-level iterator、filter block
TableCache 缓存的是 file number 到 Table + RandomAccessFile 的映射,避免频繁 open/parse。对外的接口在 table_cache.cc 能直接看到,TableCache::Get() 会先 FindTable(),再调用 Table::InternalGet()。
真正能显著减少 IO 的是 filter block。Table::InternalGet() 在定位 data block handle 之后,会先做一次 KeyMayMatch,如果 filter 明确给出“不可能”,连 data block 都不会读。这种设计对 miss-heavy 的随机读真的是血赚
读路径之 DBImpl::Get 先 pin 住对象再解锁
DBImpl::Get() 这段代码我个人很喜欢,他的锁策略非常干净:拿到 snapshot sequence 之后,把 mem_、imm_、current 都 Ref() 住,然后立刻解锁去做真正的查找,减少 mutex hold time
1 | |
这种写法本质是在用引用计数把对象生命周期 pin 住,后台 compaction 和 RemoveObsoleteFiles() 就算在跑,也不会与当前读线程依赖的版本视图造成 collision。读路径最后还会根据 Version::UpdateStats() 的结果触发 seek compaction。
看到没,闭环了,这就是读放大被量化之后的工程闭环
VersionSet = MANIFEST + VersionEdit
VersionSet 维护每层有哪些文件、每个文件的 smallest/largest internal key、file_size、allowed_seeks,并负责把“下一次该 compact 哪一层”变成一个可量化决策
MANIFEST 记录的是版本变更历史,格式是 log append-only。每次生成新 SST、删除旧 SST,都会通过 VersionEdit 追加进 manifest。CURRENT 文件只是一个指针,指向最新的 manifest。这个设计的好处很实用:元数据恢复变成顺序读 log,坏处是 manifest 会增长。
所以 LevelDB 会在合适时机生成新的 manifest 版本,把旧的 drop 掉,避免占用空间无限增长变成良子(划掉。具体逻辑是每次
DB::Open()时检查大小,超过 max_file_size(默认 2MB)就重建,这也导致了长期不重启的服务 MANIFEST 会持续增大,直到机器 reboot
比如有这样一个旧的 manifest:

其实可以合并每次的 delta,等效压缩成下面这张表:

allowed_seeks 是 seek compaction 的核心指标。读路径在某个 table 上频繁 seek,会不断消耗 allowed_seeks,到阈值后把文件标记为 file_to_compact_,后台优先 compact 它,用空间写放大换读放大下降
再往深一层看,VersionSet::Finalize() 其实就是它的预算编制环节:遍历每一层,算一个 compaction score,找出当前最需要被 compact 的 level,然后把结果写进 v->compaction_level_ 和 v->compaction_score_
这里最有意思的是对 level-0 的特殊对待。level-0 的 score 不是用字节数去除以 level size limit,而是用文件数去除以 config::kL0_CompactionTrigger。原因很工程化,而且直接写在源码注释里:一方面 write buffer 变大时,单个 L0 文件也可能变大吧,如果还按字节数做阈值,会更频繁触发 L0 compaction,后台压力上来之后反而把前台写延迟的尾部拉长;另一方面 L0 文件之间存在 overlap,读路径必须把多个文件做归并式查找,文件数一多,读放大立刻变得很难看,尤其是在 write buffer 小、压缩比高、或者覆盖写和删除很多的时候
可以直接看这段逻辑:
1 | |
它的本质是把 L0 的系统形态风险显式量化成一个单独维度:对 L0 来说,文件个数本身就是危险信号,跟总字节数不是一回事
Compaction:多路归并、drop 规则、以及“先保证系统形态别失控”
后台调度在 DBImpl::MaybeScheduleCompaction(),真正干活在 BackgroundCompaction():先 flush imm_,再 versions_->PickCompaction(),最后 DoCompactionWork()
DoCompactionWork() 是一个很标准的多路归并:它会拿到 versions_->MakeInputIterator(),顺序扫描输入迭代器,把输出写到 TableBuilder。输出文件到达 MaxOutputFileSize() 会切文件,这样 compaction 的粒度不会太粗
更有工程味的是 drop 规则。它用 smallest_snapshot 保证 snapshot 语义不被破坏,同时基于 internal key 的 sequence 做去重:同一个 user key 的旧版本会被 drop;deletion marker 在满足 base level 条件时会被 drop,避免 tombstone 永久下沉
在 DBImpl::DoCompactionWork() 里能看到这段关键逻辑:
1 | |
这段规则其实就是 LSM 的核心:读路径看见的是“最新可见版本”,后台 compaction 负责把历史版本和 tombstone 清掉,最终把空间放大控制住
崩溃恢复之 WAL replay + MANIFEST 恢复,durability 边界在哪

恢复入口在 DBImpl::Recover()。它先通过 versions_->Recover() 恢复版本元数据,再扫描比 manifest 记录更新的 log file,用 RecoverLogFile() 顺序读 record,解析成 WriteBatch,再 InsertInto(mem) 重建 memtable。memtable 超过阈值会直接 flush 成 level-0 SST,并通过 VersionEdit 记到 manifest
这套恢复逻辑配合 WAL checksum,保证了 crash-consistent:元数据靠 manifest,数据增量靠 WAL。真正的耐久性边界仍然取决于写入是否 sync,LevelDB 把这个选择权交给了调用方
性能调参
LevelDB 的性能调优,如果只盯一个参数,很容易调崩。更稳的视角是放大因子
写放大一般和 compaction 粒度、level size limit、L0 文件数量波动相关。write_buffer_size 大一点会降低 flush 频率,L0 形态更平滑,但也会让 crash 恢复时 log replay 变长。max_file_size 会影响 SST 数量和 compaction 切分粒度,进而影响写放大和后台 CPU。
读放大则更多跟 filter block、block cache 命中率、以及 L0 overlap 相关。Bloom filter 的 bits-per-key 往往是性价比极高的开关;ReadOptions::fill_cache 在离线 scan 时建议关掉,不然很容易把线上热点 block 顶出 cache
还有一个纯 CPU 的坑:comparator 的成本。LevelDB 很多结构默认 comparator 很便宜,但如果在 comparator 里做重逻辑,跳表比较、block prefix compression、index key shortening 这些地方都会产生较大的 lag
结语
LevelDB 这套实现说白了就是把随机写变成顺序追加,把不确定性丢给后台,用版本系统让读写都能在一个一致视图下运转,再用一堆细粒度的缓存和 iterator 抽象把 IO 成本折叠起来。










